BACKGROUND
In cost-effectiveness analysis (CEA), a life-time horizon is commonly used to simulate a chronic disease. Data for mortality are normally derived from survival curves or Kaplan-Meier curves published in clinical trials. However, these Kaplan-Meier curves may only provide survival data up to a few months to a few years. Extrapolation to a lifetime horizon is possible using a series of methods based on parametric survival models (e.g., Weibull, exponential); but performing these projections can be challenging without the appropriate data and software.
This blog provides a practical, step-by-step tutorial to estimate a parameter method (Weibull) from a survival function for use in CEA models. Specifically, I will describe how to:
Capture the coordinates of a published Kaplan-Meier curve and export the results into a *.CSV file
Estimate the survival function based on the coordinates from the previous step using a pre-built template
Generate a Weibull curve that closely resembles the survival function and whose parameters can be easily incorporated into a simple three-state Markov model
MOTIVATING EXAMPLE
We will use an example dataset from Stata’s data library. (You can use any published Kaplan-Meier curve. I use Stata's data library for convenience.) Open Stata and enter the following in the command line:
use http://www.stata-press.com/data/r15/drug2b sts graph, by(drug) risktable
You should get a Kaplan-Meier curve that illustrates the survival probability of two different drugs (Figure 1). The Y-axis denotes the survival probability and the X-axis denotes the time in months. Below the figure is the number at risk for the two drug comparators. We will need this to generate our Weibull curves. (If possible, find a Kaplan-Meier curve with the number at risk. It will make the Weibull curve generation easier.) Alternative methods exist to use Kaplan-Meier curves without the number at risk, but they will not be discussed in this tutorial.
Figure 1. Kaplan-Meier curve.
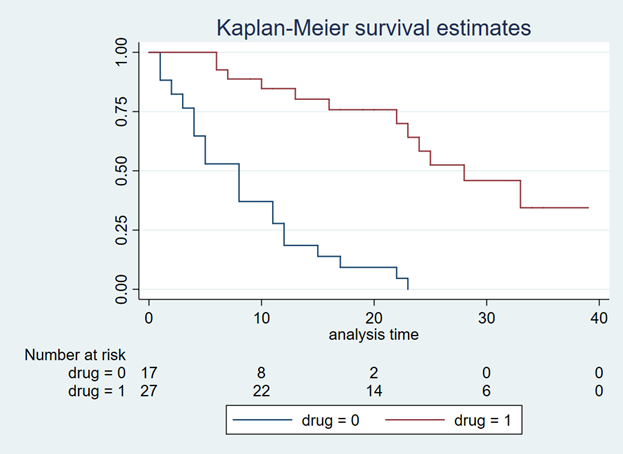
You will need to download the “Engauge Digitizer” application to convert this Kaplan-Meier curve into a *.CSV file with the appropriate data points. This will help you to develop an accurate survival curve based on the Kaplan-Meier curve. You can download the “Engauge Digitizer” application here: https://markummitchell.github.io/engauge-digitizer/
After you download “Engauge Digitizer,” open it and import the Kaplan-Meier file. Your interface should look like the following:
Figure 2. Engauge Digitizer interface.

The right panel guides you in digitizing your Kaplan-Meier figure. Follow this guide carefully. I will not go into how to use “Engauge Digitizer;” however a YouTube video tutorial to use Engauge Digitizer was developed by Symmetry Solutions and is available here.
We will use the top Kaplan-Meier curve (which is highlighted with blue crosshairs in Figure 3) to generate our Weibull curves.
Figure 3. Select the top curve to digitize.

After you digitize the figure, you will export the data as a *.CSV file. The *.CSV file should have two columns corresponding to the X- and Y-axes of the Kaplan-Meier figure. Figure 4 has the X values end at row 20 to fit onto the page, but this extends till the end of the Kaplan-Meier time period, which is 40.
Figure 4. *.CSV file generated from the Kaplan-Meier curve (truncated to fit onto this page).

I usually superimpose the “Engauge Digitizer” results with the actual Kaplan-Meier figure to prove to myself (and others) that the curves are exactly the same (Figure 5). This is a good practice to convince yourself that your digitized data properly reflects the Kaplan-Meier curve from the study.
Figure 5. Kaplan-Meier curve superimposed on top of the Engauge Digitizer curve.

Now, that we have the digitized version of the Kaplan-Meier, we need to format the data to import into the Weibull curve generator. Hoyle and Henley wrote a paper that explains their methods for using the results from the digitizer to generate Weibull curves.[1] We will use the Excel template they developed in order to generate the relevant Weibull curve parameters. (The link to the Excel template is provided at the end of this tutorial.)
I always format the data to match the Excel template developed by Hoyle and Henley. The blue box indicates the number at risk at the time points denoted by Figure 1 and the red box highlights the evenly spaced time intervals that I estimated (Figure 6).
Figure 6. Setting up your data using the template from Hoyle and Henley.

In order to find the survival probability at each “Start time” listed in the Excel template by Hoyle and Henley, linear interpolation is used. [You can use other methods to estimate the survival probability between each time points given the data on Figure 3 (e.g., last observation carried forward); however, I prefer to use linear interpolation.] In Figure 7, the survival probabilities (Y) correspond to a time (X) that was generated by the digitizer. Now, we want to find the Y value corresponding to the X values on the Excel template.
Figure 7. Generating the Y-values using linear interpolation.

Figure 8 illustrates how we apply the linear interpolation to estimate the Y value that corresponds with the X values from the Excel template developed by Hoyle and Henley. For example, if you were interested in finding the Y value at X = 10, the you would need to input the following into the linear interpolation equation using the following expression:

This yields a Y value of 0.866993, which is approximately 0.87.
Figure 8. Y values are generated using linear interpolation.

After generating the Y values corresponding to the Start time from Figure 5, you can enter them into the Excel template by Hoyle and Henley (Figure 9). Figure 9 illustrates the inputted survival probabilities into the Excel template.
Figure 9. Survival probabilities are entered after estimating them from linear interpolation.

After the “Empirical survival probability S(t)” is populated, you will need to go to the “R Data” worksheet in the Excel template and save this data as a *.CSV file. In this example, I saved the data as “example_data.csv” (Figure 10).
Figure 10. Data is saved as “example_data.csv.”

Then I used the following R code to estimate the Weibull parameters. This R code is located in the “Curve fitting ‘R’ code” in the Excel templated developed by Hoyle and Henley. (I modified the R code written by Hoyle and Henley to allow for a *.CSV file import.)
rm(list=ls(all=TRUE))
library(survival)
# Step 4. Update directory name and text file name in line below
setwd("insert the folder path where the data is stored")
data<- read.csv("example_data.csv")
attach(data)
data
times_start <-c( rep(start_time_censor, n_censors), rep(start_time_event, n_events) )
times_end <-c( rep(end_time_censor, n_censors), rep(end_time_event, n_events) )
# adding times for patients at risk at last time point
######code does not apply because 0 at risk at last time point
######code does not apply because 0 at risk at last time point
# Step 5. choose one of these function forms (WEIBULL was chosen for the example)
model <- survreg(Surv(times_start, times_end, type="interval2")~1, dist="exponential") # Exponential function, interval censoring
model <- survreg(Surv(times_start, times_end, type="interval2")~1, dist="weibull") # Weibull function, interval censoring
model <- survreg(Surv(times_start, times_end, type="interval2")~1, dist="logistic") # Logistic function, interval censoring
model <- survreg(Surv(times_start, times_end, type="interval2")~1, dist="lognormal") # Lognormal function, interval censoring
model <- survreg(Surv(times_start, times_end, type="interval2")~1, dist="loglogistic") # Loglogistic function, interval censoring
# Compare AIC values
n_patients <- sum(n_events) + sum(n_censors)
-2*summary(model)$loglik[1] + 1*2 # AIC for exponential distribution
-2*summary(model)$loglik[1] + 1*log(n_patients) # BIC exponential
-2*summary(model)$loglik[1] + 2*2 # AIC for 2-parameter distributions
-2*summary(model)$loglik[1] + 2*log(n_patients) # BIC for 2-parameter distributions
intercept <- summary(model)$table[1] # intercept parameter
log_scale <- summary(model)$table[2] # log scale parameter
# output for the example of the Weibull distribution
lambda <- 1/ (exp(intercept))^ (1/exp(log_scale)) # l for Weibull, where S(t) = exp(-lt^g)
gamma <- 1/exp(log_scale) # g for Weibull, where S(t) = exp(-lt^g)
(1/lambda)^(1/gamma) * gamma(1+1/gamma) # mean time for Weibull distrubtion
# For the Probabilistic Sensitivity Analysis, we need the Cholesky matrix, which captures the variance and covariance of parameters
t(chol(summary(model)$var)) # Cholesky matrix
# Simulate variability of mean for Weibull
library(MASS)
simulations <- 10000 # number of simulations for standard deviation of mean
sim_parameters <- mvrnorm(n=simulations, summary(model)$table[,1], summary(model)$var ) # simulates simulations from multivariate normal
intercepts <- sim_parameters[,1] # intercept parameters
log_scales <- sim_parameters[,2] # log scale parameters
lambdas <- 1/ (exp(intercepts))^ (1/exp(log_scales)) # l for Weibull, where S(t) = exp(-lt^g)
gammas <- 1/exp(log_scales) # g for Weibull, where S(t) = exp(-lt^g)
means <- (1/lambdas)^(1/gammas) * gamma(1+1/gammas) # mean times for Weibull distrubtion
sd(means) # standard deviation of mean survival
# consider adding this (from Arman Oct 2016) to plot KM
km <- survfit(Surv(times_start, times_end, type="interval2")~ 1)
summary(km)
plot(km, xmax=600, xlab="Time (Days)", ylab="Survival Probability")
There are several elements generated by the above R code that you need to record, including the intercept and log-scale:
> intercept [1] 3.494443 > log_scale [1] -0.5436452
Once you have this, input them into the Excel template sheet titled “Number events & censored,” which is the same sheet you used to generate the survival probabilities after entering the data from the “Engauge Digitizer.” Figure 11 illustrates where these parameters are entered (red square).
Figure 11. Enter the intercept and log scale parameters into the Excel template developed by Hoyle and Henley.

You can check the fit of the Weibull curve to the observed Kaplan-Meier curve in the tab “Kaplan-Meier.” Figure 12 illustrates the Weibull fit’s approximation of the observed Kaplan-Meier curve.
Figure 12. Weibull fit (red curve) of the observed Kaplan-Meier curve (blue line).

From Figure 11, we also have the lambda (λ=0.002433593) and gamma (γ=1.722273465) parameters which we’ll use to simulate survival using a Markov model.
SUMMARY
In the next blog, we will discuss how to use the Weibull parameters to generate a survival curve using a Markov model. Additionally, we will learn how to extrapolate the survival curve beyond the time period used to generate the Weibull parameters for cost-effectiveness studies that use a lifetime horizon.
REFERENCES
Location of Excel spreadsheet developed by Hoyle and Henley (Update 02/17/2019: I learned that Martin Hoyle is not hosting this on his Exeter site due to a recent change in his academic appointment. For those interested in getting access to the Excel spreadsheet used in this blog, please download it at this link).
Update: 12 January 2023 - The old link to the YouTube video on Engauge was broken. A new link was identified that provided the same content on how to use Engauge.
Location of the Markov model used in this exercise is available in the following link:
https://www.dropbox.com/sh/ztbifx3841xzfw9/AAAby7qYLjGn8ZfbduJmAsVva?dl=0
Design with Greg. “Engauge: A Free Tool for Engineering that pairs great with Excel.” Available at the following url: https://www.youtube.com/watch?v=i1bEFovvvbM
Engauge Digitizer: Mark Mitchell, Baurzhan Muftakhidinov and Tobias Winchen et al, "Engauge Digitizer Software." Webpage: http://markummitchell.github.io/engauge-digitizer [Last Accessed: February 3, 2018].
Hoyle MW, Henley W. Improved curve fits to summary survival data: application to economic evaluation of health technologies. BMC Med Res Methodol 2011;11:139.
ACKNOWLEDGMENTS
I want to thank Solomon J. Lubinga for helping me with my first attempt to use Weibull curves in a cost-effectiveness analysis. His deep understanding and patient tutelage are characteristics that I aspire to. I also want to thank Elizabeth D. Brouwer for her comments and edits, which have improved the readability and flow of this blog. Additionally, I want to thank my doctoral dissertation chair, Beth Devine, for her edits and mentorship.