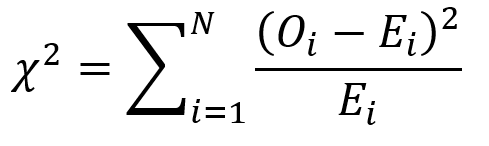BACKGROUND
Every Tuesdays, my friends and I enjoy playing role playing games (RPGs), especially table top RPGs such as Dungeons & Dragons (D&D). Every week, we get together and pull out our laptops, character sheets, and review our previous notes to return to the fictional fantasy worlds we created (or were created for us) and do battle, solve mysteries, and tell stories over some ciders (and Le Croix). This ritual is important because it allows us to disconnect from the real world and allow our imaginations to run wild. After every session, we think about the various actions that took place and review how things would have been different if the roll of a dice went a different way.
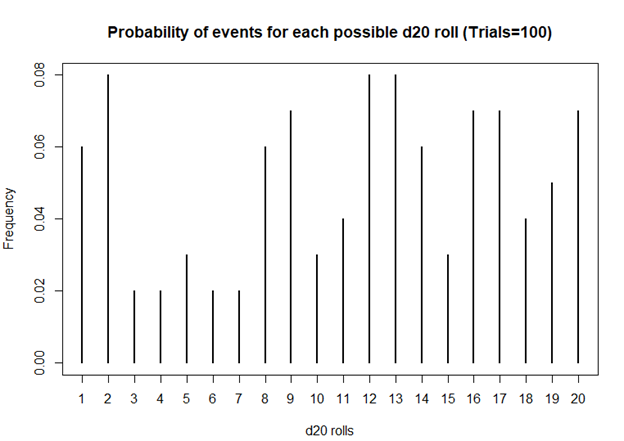
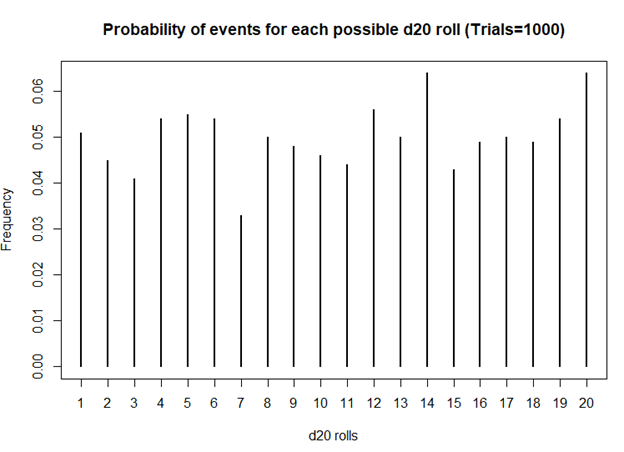
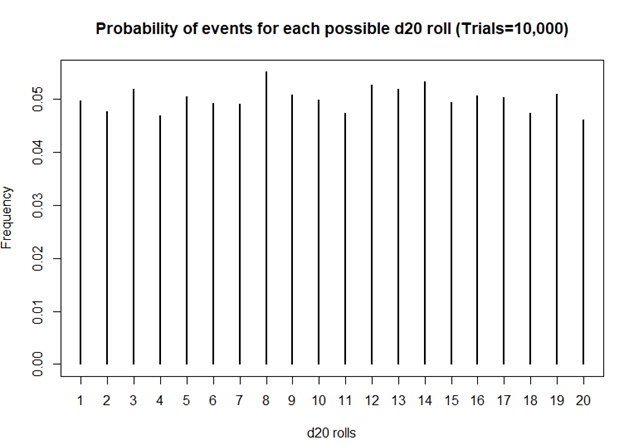
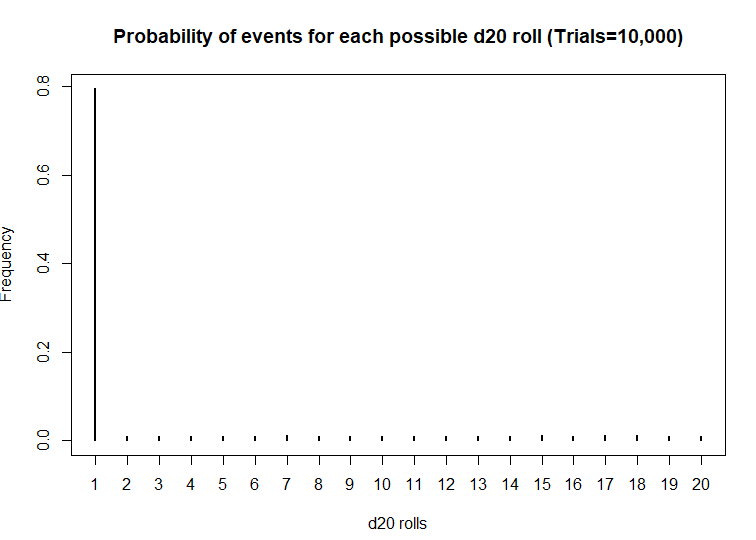
I first started playing D&D Second Edition when I was a kid after I was exposed to it at a comic book store (Golden Apple Comics in Los Angeles). I still remember the strange colorful dice rolling on a table top mat and people scratching away at paper using stats that I wasn’t familiar with. In high school, my friends and I would play different campaigns from the D&D and Forgotten Realms worlds, creating characters based on rule books using statistics and probabilities. The key ingredient with any adventure is having your fate determined by a single dice roll. The iconic dice in RPG is the d20 or the 20-sided dice. A d20 dice is usually used to determine whether you “hit” your opponent, use your skills to identify if a trap has been set or whether or not you can charm your way out of an unnecessary fight. Often times than not, there is the chance that a critical fail (a d20 roll of 1) can occur. When this happens, you fail to hit your opponent and trip over yourself during combat, miss the trap and activate it killing someone in your party, or pissing off the non-playable character (NPC) and having them attack you. Not only will something go wrong, it will go wrong spectacularly. So, it’s only natural that we look at the d20 that was rolled and ask, “Is my d20 killing me?”
Luckily, there is a statistical test that we can use to answer this common question.
CHI SQUARE TEST
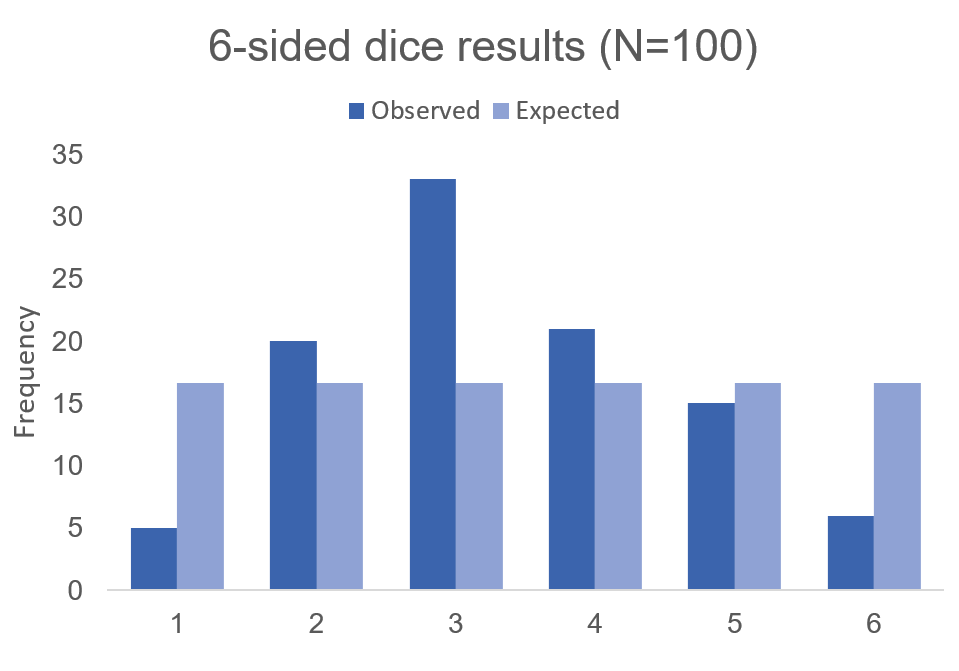
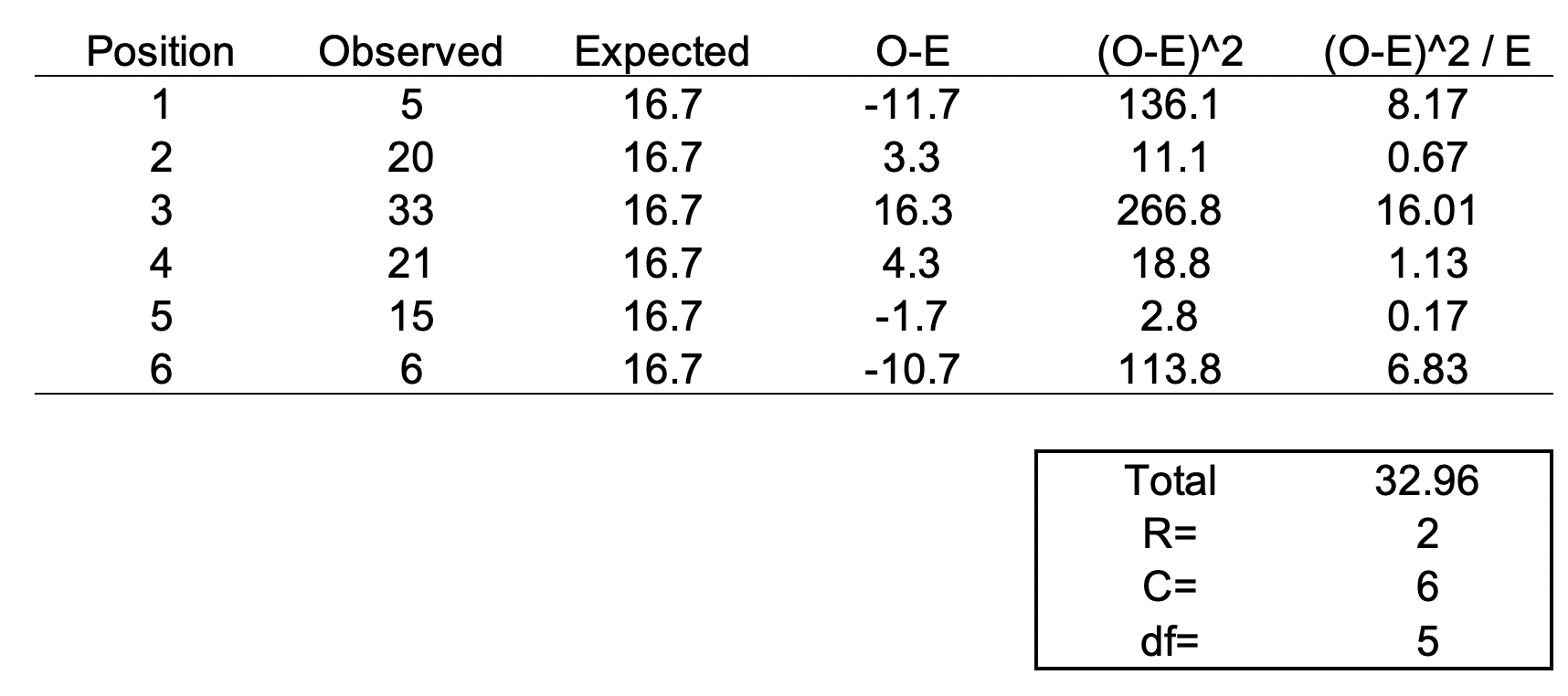
The chi square test is one of the most common statistical tests performed in sciences. In its simplest form, the chi square test is used to detect whether the observed frequencies are different from the expected frequencies across different categories. For example, in a 6-sided dice, the probability that the number 6 will land is 16.7% or 1/6. This is true for every value of the 6-sided dice if it was unbiased.