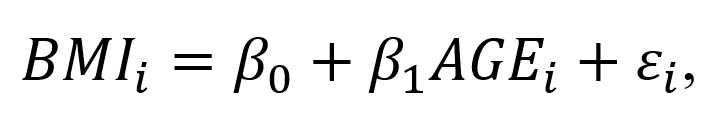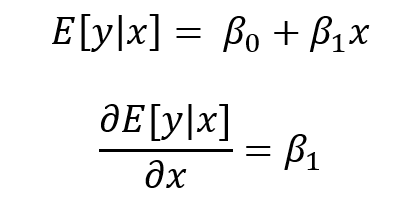where y_i denotes the outcome (dependent) variable for subject i, beta0 denotes the intercept, beta1 is the model coefficient that denotes the change in y due to a 1-unit change in x, and epsilon_i is the error term for subject i.
A 1-unit increase in x is associated with some change in the outcome y. This finding may explain predictor variable x’s impact on outcome variable y, but it doesn’t not tell us the impact of a representative or prototypical case.
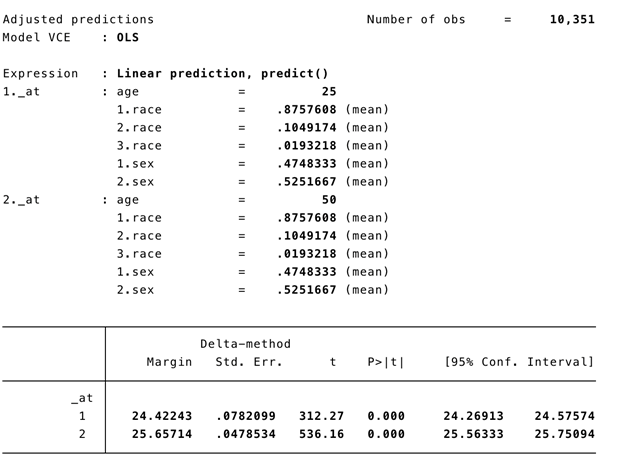
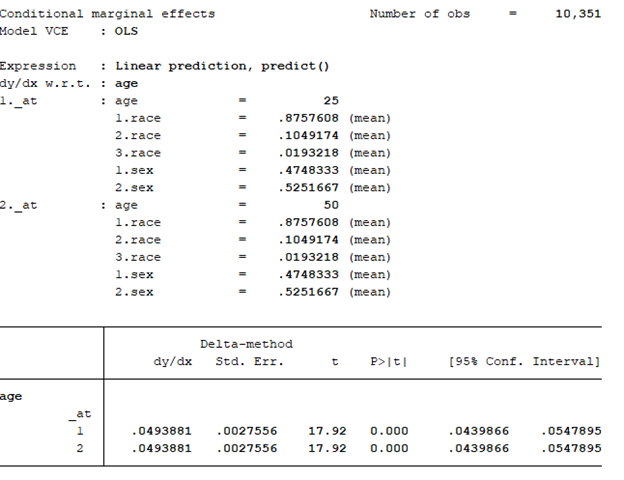
The marginal effect allows us to examine the impact of variable x on outcome y for representative or prototypical cases. For example, Stata’s margins command can tell us the marginal effect of body mass index (BMI) between a 50-year old versus a 25-year old subject.
There are three types of marginal effects of interest:
1. Marginal effect at the means (MEM)
2. Average marginal effect (AME)
3. Marginal effect at representative values (MER)
Each of these marginal effects have unique interpretations that will impact how you examine the regression results. (We will focus on the first two, since the third one is an extension of the AME.) The objective of this tutorial is to review these marginal effects and understand their interpretations through examples using Stata.
MOTIVATING EXAMPLE
We will use the Second National Health and Nutrition Examination Survey (NHANES) data from the 1980s, which can be found in Stata’s library using the following command: