The bysort command has the following syntax:
bysort varlist1 (varlist2): stata_cmd
Stata orders the data according to varlist1 and varlist2, but the stata_cmd only acts upon the values in varlist1. This is a handy way to make sure that your ordering involves multiple variables, but Stata will only perform the command on the first set of variables.
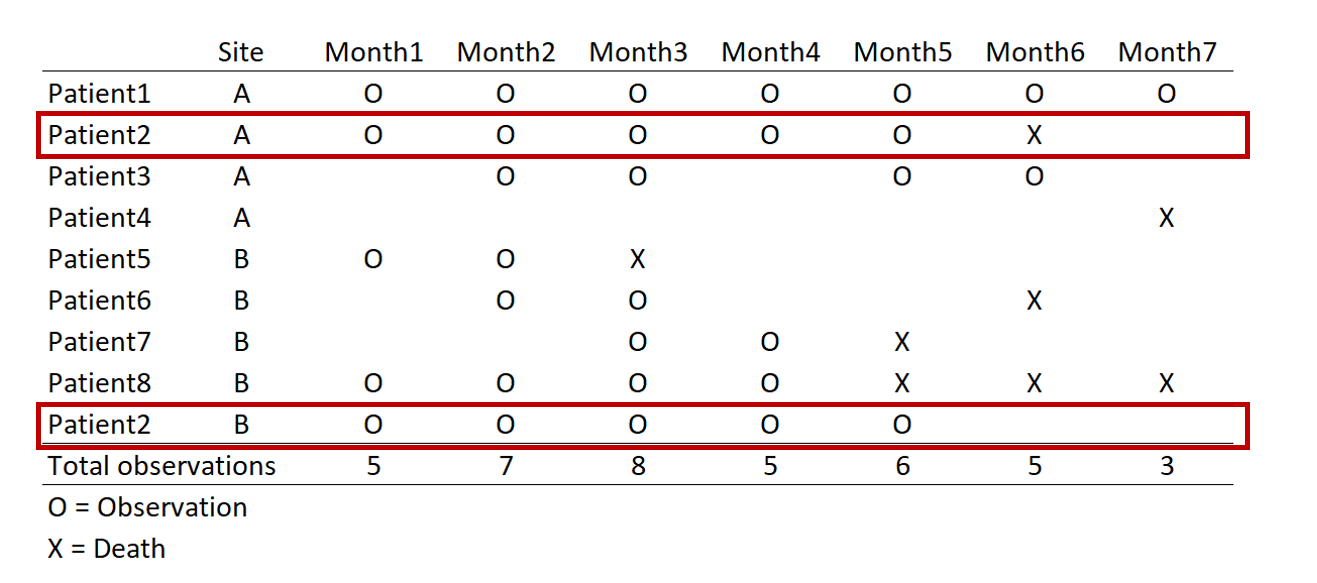
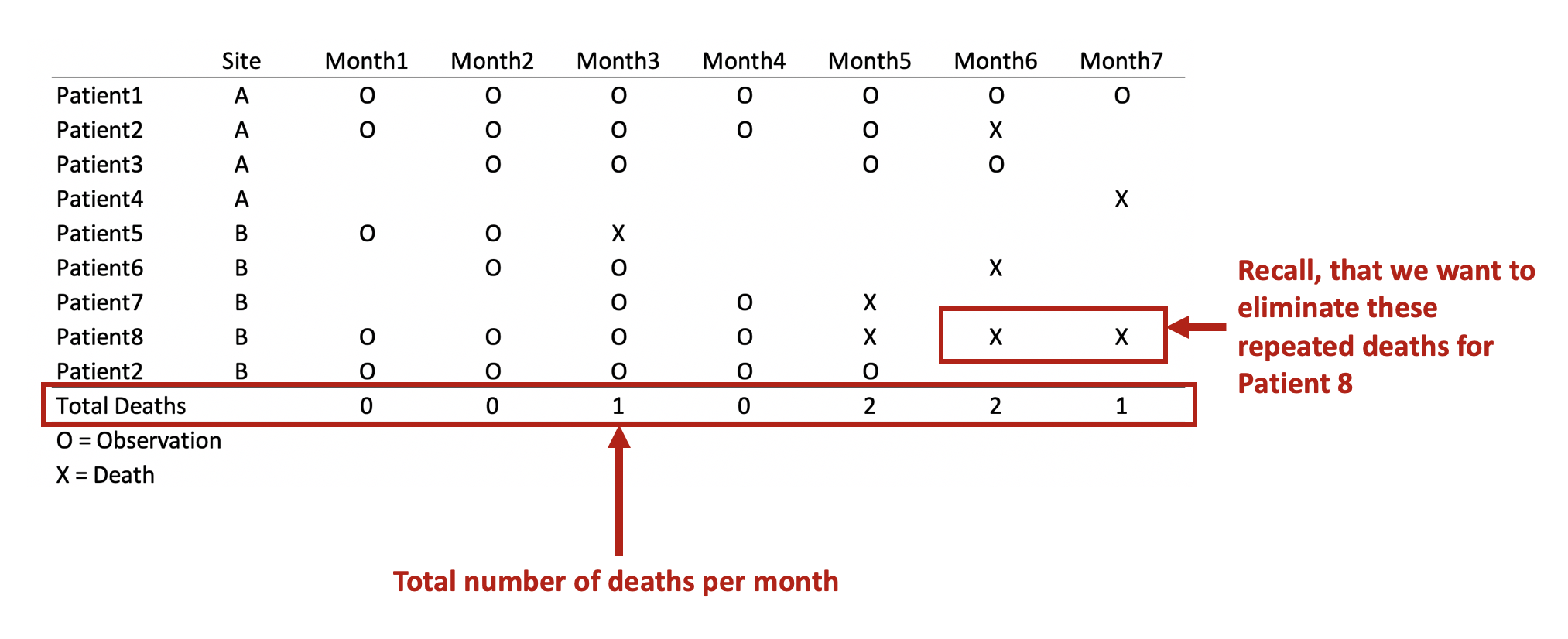
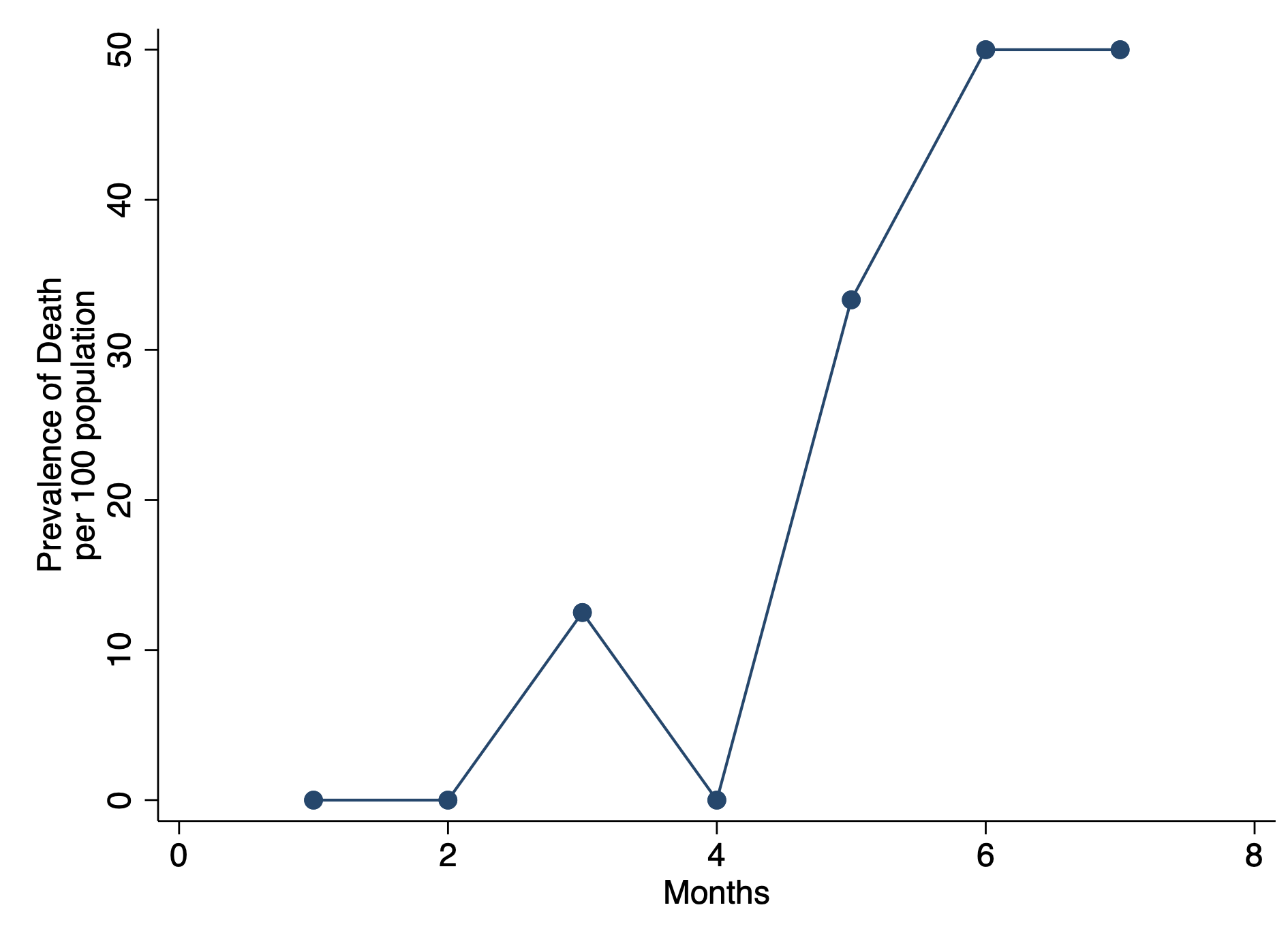
REMOVE REPEATED DEATHS FROM PATIENT 8
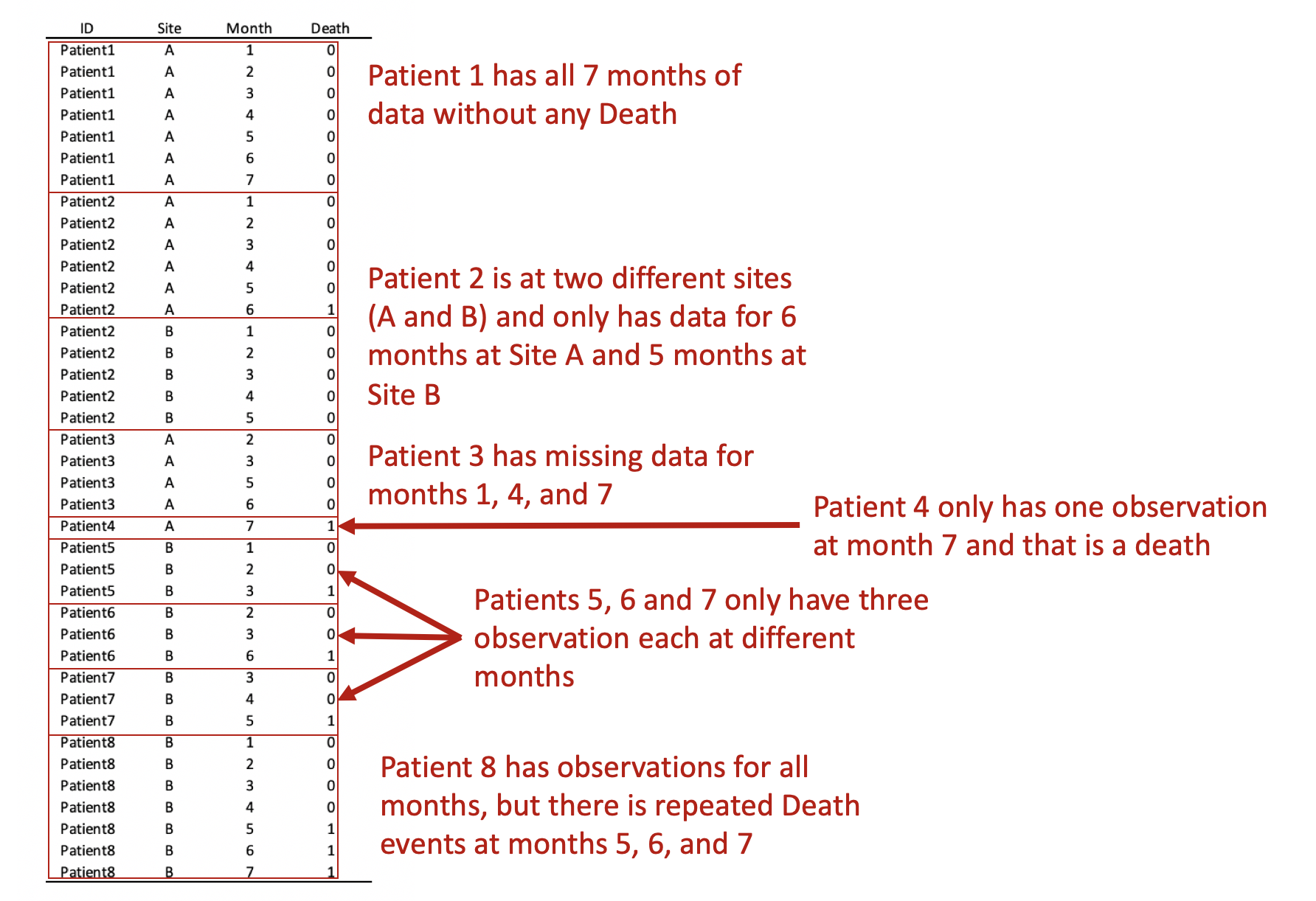
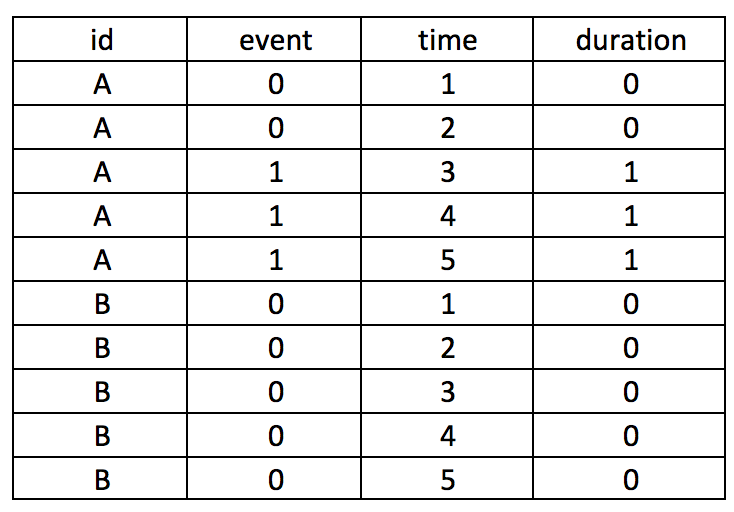
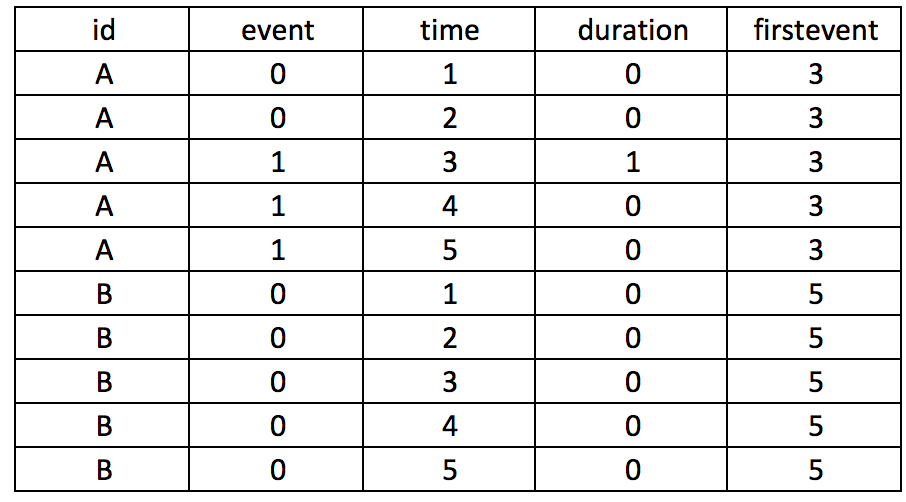
First, we want to make sure we eliminate the repeated deaths from Patient 8. We can do this using the bysort command and summing the values of Death. Since Death == 1, we can sum up the total Deaths a patient experiences and drop those values that are greater than 1—because a patient can only die once.
***** Identify patients with repated death events.
bysort id site (month death): gen byte repeat_deaths = sum(death==1)
drop if repeat_deaths > 1
The alternative methods use the sort command:
* Alternative Method 1:
by id site (month death), sort: gen byte repeat_deaths = sum(death==1)
drop if repeat_deaths > 1
* Alternative Method 2:
sort id site (month death)
by id site (month death): gen byte repeat_deaths = sum(death ==1)
drop if repeat_deaths > 1