
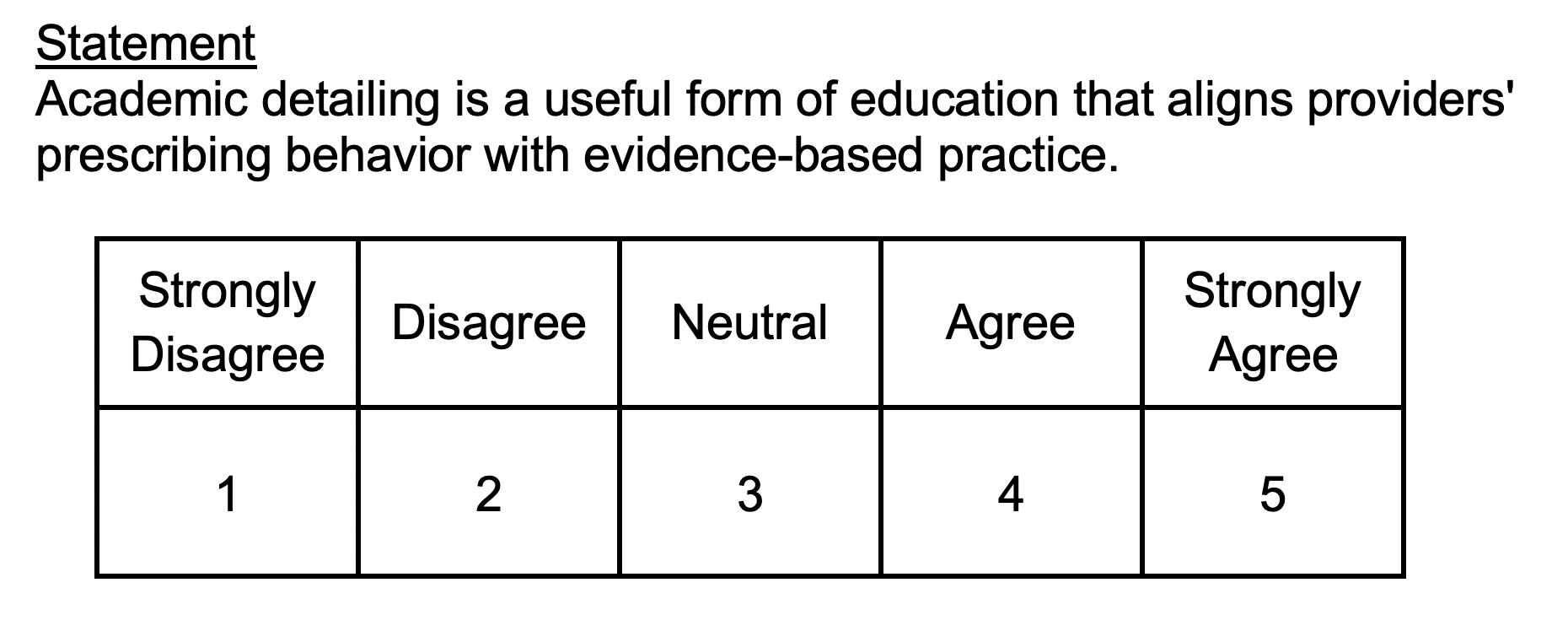
INTRODUCTION
Although data visualization has established itself as an important part of any scientific report and presentation, it has largely depended on the contributions of unique individuals. Several of these individuals have been mentioned throughout this data visualization series such as Edward R. Tufte, William S. Cleveland, and Cole Nussbaumer Knaflic. Each of these individuals have advanced the field of data visualization by sharing their philosophy and style to improve how data can be visualized easily and thoughtfully. But one person in history made the greatest advancements with data visualization in a time when war and public health became important partners in improving health care—Florence Nightingale.
![Source: Duyckinick, Evert A. Portrait Gallery of Eminent Men and Women in Europe and America. New York: Johnson, Wilson & Company, 1873. [Link]](https://images.squarespace-cdn.com/content/v1/58cde3fcdb29d633eb688e9e/1568496739332-8DTOJ4ICBOXGQYP8UQZQ/1024px-Florence_Nightingale_three_quarter_length.jpg)
Source: Duyckinick, Evert A. Portrait Gallery of Eminent Men and Women in Europe and America. New York: Johnson, Wilson & Company, 1873. [Link]
CAREER
Florence Nightingale (1820–1910) was a nurse, statistician, and social reformer who is famously known for treating British troops during the Crimean War. During the conflict where nations from Britain, France, Sardinia, Russia, and the Ottoman Empire mobilized for war between 1853-1856, more than 21,000 British troops died; only 5,000 deaths were attributable to actual battle. Most troops died not because of combat, but due to common camp diseases such as cholera, dysentery, and typhoid. Nightingale’s reforms helped to reduce non-combat related mortality in the British Army and earned her the accolade of Henry Wadsworth Longfellow who immortalized to her as “The Lady with the Lamp” in one of his poems.
When she was appointed Superintendent of the Female Nurses in the Hospitals in the East by Sydney Herbert, the Secretary of War, in 1854, she brought with her a team of 38 volunteer nurses and an innovative and determined mind.[1] Armed with her classical training and determination to get thing done, Nightingale began implementing reforms in the British Military Hospital Barracks. She instituted sterilized laundry and hand washing sanitation protocols, raised funds, and improved hospital administration. Moreover, during her tour in the Crimean War, Nightingale collected an impressive collection of data about mortality in the army, which were later used in several reports to the Royal Commission on the Health of the Army and Queen Victoria.
When Nightingale returned from the war, she created the Nightingale Training School at St Thomas’ Hospital (now called the Florence Nightingale Faculty of Nursing and Midwifery and & Palliative Care at King’s College London) to train a new generation of nurses using her ideas and philosophies in 1860.
DATA VISUALIZATION
In addition to her accomplishments in nursing, public health, and social reform, Nightingale has been hailed as a pioneer in using statistics and data visualization to maximum effect and changed policies regarding how soldiers were cared for in military hospitals. Using data she collected, Nightingale went about describing them in visual detail. She is famous for creating a new type of diagram that was meant to fuel the narrative she was arguing called the Nightingale rose or wedge diagram (Figure 1). (Other names for the rose diagram include the coxcomb and polar area diagrams.)
Figure 1. Florence Nightingale rose diagram illustrated the causes of death in the British Army. 1858. Source: [Link]
The rose diagrams were generated using the following table from Nightingales report to the Royal Commission on the Health of the Army (Figure 2). The rose diagram takes advantage of the radii of the segments or petals in addition to their length from the center to generate areas that reflected the scale and size of the different months. Each petal (segment) represented a a month and the estimated mortality rate (deaths per 1000 population). From each petal of the rose diagram, a reader can discern the scale of the mortality by month relative to other months based on the area. This type of visual aid prompted to military to review how the soldiers were being treated and reformed how the military operated.
Figure 2. Estimated Average Monthly Strength of the Army; and the deaths and Annual Rate of Mortality per 1000 in each month, from April 1854, to March 1856.
![Source: Mortality of the British Army, At Home, At Home and Abroad, and During the Russian War, As Compared with the Mortality of the Civil Population in England. 1858. Harrison and Sons, St. Martin's Lane. [Link] [Accessed September 11, 2019].](https://images.squarespace-cdn.com/content/v1/58cde3fcdb29d633eb688e9e/1568496963927-4OTDFW5EDM6WK2X8OD1C/Figure+3+-+table.png)
Source: Mortality of the British Army, At Home, At Home and Abroad, and During the Russian War, As Compared with the Mortality of the Civil Population in England. 1858. Harrison and Sons, St. Martin's Lane. [Link] [Accessed September 11, 2019].
Legacy
Nightingale was relentless in her pursuits; she stood up and challenged the establishment of British male dominance in the military and at the hospitals. In doing so, she brought about reform that saved lives and changed the way we used and viewed data. Among her many accomplishments, she was the first female member of the Royal Statistical Society and an honorary member of the American Statistical Association. In her book, Nightingale extolled the partnership between people and government in establishing public health measures as necessary and ethical:
“Let the people only see how much they can do for themselves in improving their surface drainage, in keeping their water supply free from pollution, in cleansing inside and out.
Let the Government see how much they can do for the people in introducing and stimulating better agriculture; irrigation, combined with drainage works in water-logged districts; for the two must never be separated there.
There is not a country in the world for which so much might be done as for India.
There is not a country in the world for which there is so much hope.
Only let us do it.
— Florence Nightingale [2] ”
It only seems fitting that Florence Nightingale has been immortalized by Henry Wadsworth Longfellow in his poem “Santa Filomena”:
“A lady with a lamp shall stand
In the great history of the land,
A noble type of good,
Heroic womanhood.”
REFERENCES
1. Fee E, Garofalo ME. Florence Nightingale and the Crimean War. Am J Public Health. 2010 September; 100(9): 1591. [Link]
2. Nightingale F. Life and Death in India. 1874. Spottiswoode & Co. New Street Square, London. [Link] [Accessed: September 10, 2019].
There are countless articles and sites on Florence Nightingale that you can find online. However, I found the following to be helpful in writing this article:
Andrews RJ. Florence Nightingale is a Design Hero. July 15, 2019. [Link] [Accessed: September 10, 2019].
Mathematics of Florence Nightingales’ rose diagram. [Link] [Accessed: September 11, 2019]




















































{kind=link}
{kind=link}