INTRODUCTION
In December 2019, a novel strain of coronavirus was detected in Wuhan, the capital city of the Hubei province in China. This coronavirus was designated as severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). This current iteration of the coronavirus has many similar characteristics to its earlier ancestor SARS-CoV-1,[1] which was first detected in 2003 and known simply as SARS. According to a recent study, clinical characteristics of patients in China who were infected with SARS-CoV-2 included fever (up to 88.7% who were hospitalized) and cough (67.8%).[2] The median age of patients infected was 47.0 years (IQR: 35.0-58.0) with a large distribution of 58.3% over the age of 50 years having severe symptoms. Additionally, the case fatality rate was reported to be 1.4%.
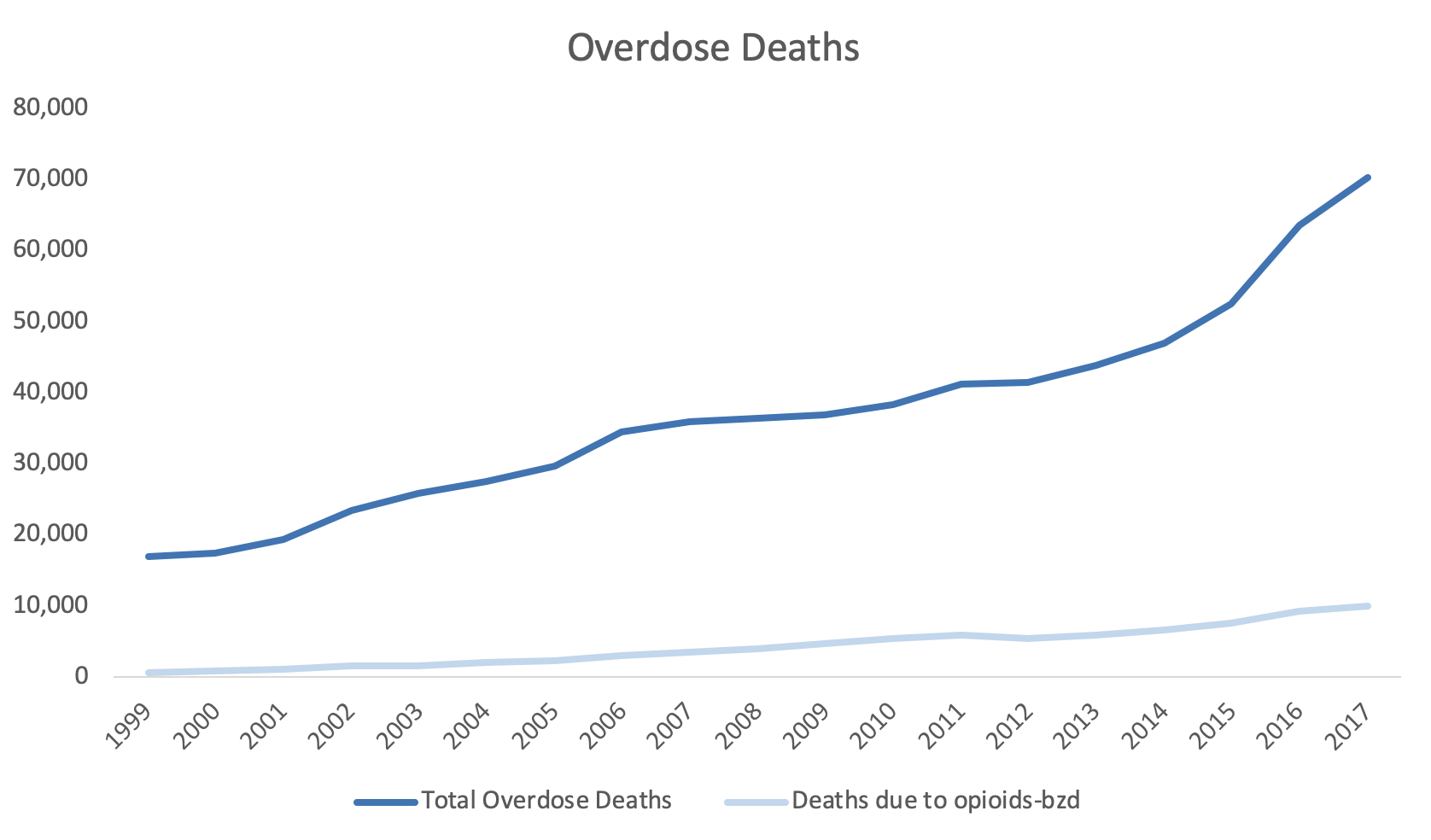
In January 2020, the World Health Organization (WHO) in regards to the SARS-CoV-2 outbreak declared a global health emergency.[3] Regardless, as SARS-CoV-2 spread across the globe into a pandemic, many countries started to report the attributable number of cases and deaths. According to the WHO, the global total of confirmed cases is at 191,127 and global deaths is at 7,807 (as reported on March 18, 2020).[4]
One of the most important tools in understanding the SARS-CoV-2 epidemic course is the epidemic curve. Epidemic curves allow epidemiologists to visualize the progression of an outbreak by surveilling the number of cases across time.[5] The epidemic curve informs epidemiologists about the pattern of the outbreak’s spread, magnitude, time to exposure, and outliers. Moreover, the epidemic curve is constantly updated as more data become available.
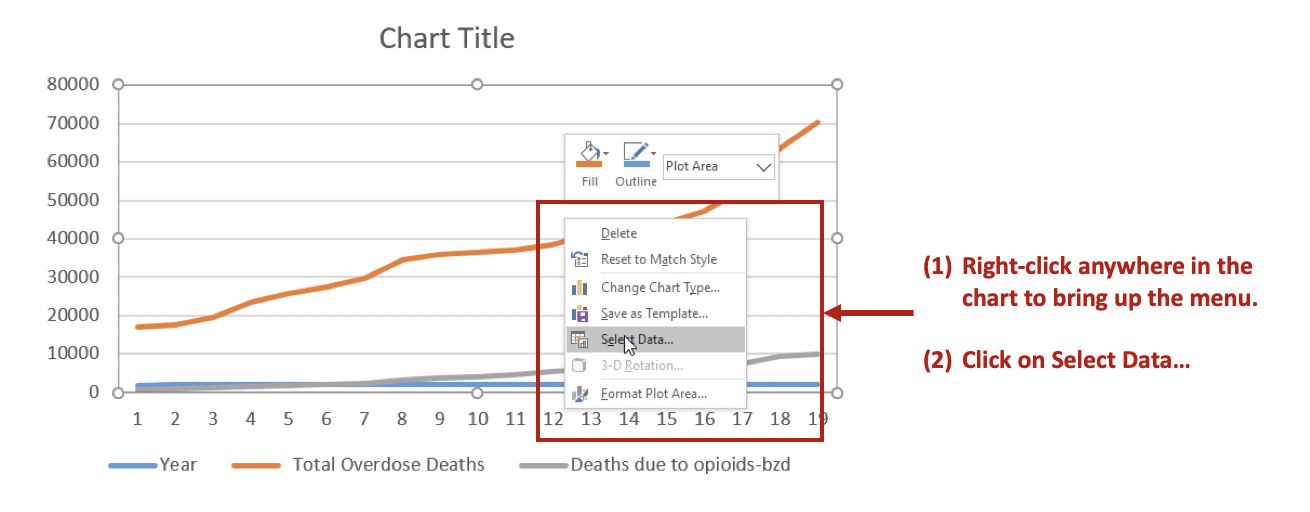
As the SARS-CoV-2 pandemic spreads to other countries, many data visualizations have been developed to help educate and inform people. Johns Hopkins University has developed a real-time dashboard with epidemic curves on the SARS-CoV-2 pandemic that is an excellent source of global cases and mortality. The Centers for Disease Control and Prevention (CDC) also has a series of data visualizations on the SARS-CoV-2 outbreak in the United States including an epidemic curve.
This article will review the features of an epidemic curve and provide a tutorial on creating one based on the available data from the CDC on the SARS-CoV-2 outbreak in the United States.
EPIDEMIC CURVE
When an outbreak happens, there is an urgency to determine when it first occurred. Epidemiologists carefully, collect data to determine who patient zero is and when the case was first identified. This gives them a starting point for when the outbreak occurred. Epidemic curves provide information on the outbreaks’ spread, magnitude, incubation period, outliers, and time trend. Key features of the epidemic curve include the number of cases on the Y-axis and the date of illness on the X-axis. Figure 1 illustrates the key features of the epidemic curve for a point-source outbreak.
Figure 1. Key features of the epidemic curve for a point-source outbreak.












![Source: Flavored Tobacco Product Use Among Middle and High School Students—United States, 2014–2018. url: link [Accessed on 17 October 2019]](https://images.squarespace-cdn.com/content/v1/58cde3fcdb29d633eb688e9e/1571371774574-86F3QCME0HOTSY5M5VFP/Figure+1.png)




![Source: Duyckinick, Evert A. Portrait Gallery of Eminent Men and Women in Europe and America. New York: Johnson, Wilson & Company, 1873. [Link]](https://images.squarespace-cdn.com/content/v1/58cde3fcdb29d633eb688e9e/1568496739332-8DTOJ4ICBOXGQYP8UQZQ/1024px-Florence_Nightingale_three_quarter_length.jpg)
![Source: Mortality of the British Army, At Home, At Home and Abroad, and During the Russian War, As Compared with the Mortality of the Civil Population in England. 1858. Harrison and Sons, St. Martin's Lane. [Link] [Accessed September 11, 2019].](https://images.squarespace-cdn.com/content/v1/58cde3fcdb29d633eb688e9e/1568496963927-4OTDFW5EDM6WK2X8OD1C/Figure+3+-+table.png)



{kind=link}
{kind=link}