
INTRODUCTION
Since the COVID-19 pandemic began on 12 December 2019, there have been several innovations in the forms of vaccinations and treatments. Of critical importance is the world-wide international support for COVID-19 vaccination. A timeline of the COVID-19 pandemic can be found at the CDC website.
The website informationisbeautiful.net has a great COVID-19 dashboard that ranks countries that have administered vaccinations.
Source: www.informationisbeautiful.net (https://informationisbeautiful.net/visualizations/covid-19-coronavirus-infographic-datapack/)
TUTORIAL
We will recreate this chart using Excel. Data can be download from my Dropbox folder or from Our World in Data website.
The data will contain information for 39 countries. These variables include the total number of vaccinations, the number of people vaccinated, the number of people who are fully vaccinated, the number of boosters, the total population, percentage of the population who are vaccinated, percentage of the population who are fully vaccinated, and the percentage of the population with boosters.
We will create a vertical bar chart for the percentage of the total population that received at least one COVID-19 vaccination. You can use these methods to recreate the vertical bar charts of the remaining figures in the figure above.
Visually inspect the data. It should look like the following.
We will us the “total_vaccinations,” “percent_vaccinated,” “percent_full_vaccinated,” and “percent_boosted” to generate the figures.
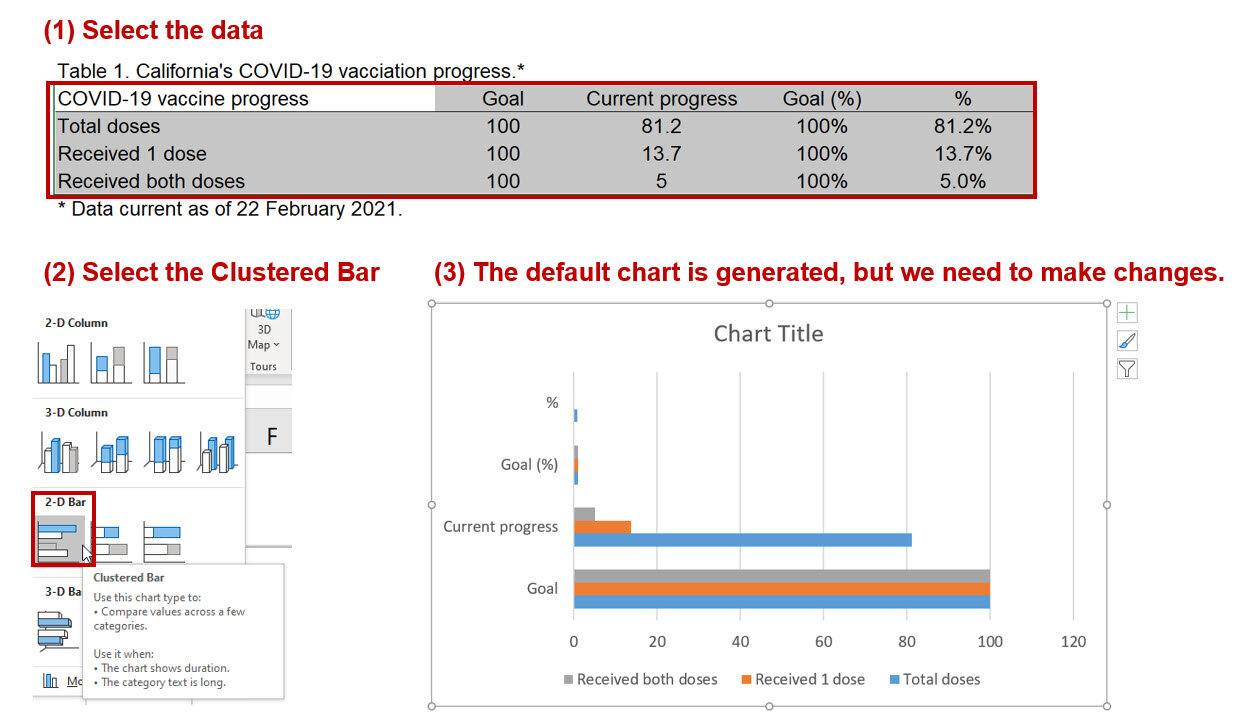
Step 1: Insert the vertical bar chart.
Once the vertical bar chart is inserted onto the Excel sheet, right click on the chart and click on “Select data.” We want to highlight the data column titled, “percent_fully_vaccinated.” For the “Series name,” enter “% fully vaccinated.”
Step 2. Edit the labels.
In the “Horizontal (Category) Axis Labels,” click on the “Edit” button and select the
location.” In the “Axis label range,” highlight the values in the “location” column. This will assign each value of the “percent_fully_vaccinated” with the country.
Step 3. Delete unnecessary labels and titles.
The figure should look like the following. We can delete the x-axis, the axis title, and the chart title. Extend the chart so that you can view all the countries. You can also narrow the chart so that it will resemble the size of the informationisbeautiful.net figures.
Step 4. Create a progress bar
We will add a progress bar, which will allow us to see how much of the population is fully vaccinated. This requires us to use the “full_bar” column which has a value of “1” for each country. This value represents a 100% progress goal.
Right-click on the chart and add a new data entry. Select the data under the column called “full_bar.” The values are all “1” to represent a 100% progress bar.
The chart will have two bars for each country; one bar represents the percentage of the population that is fully vaccinated, and other bar represents 100% progress. We need to edit the overlay and the width of the bar to match the ones on the informationisbeautiful.net charts.
Right-click the chart and select “Format Data Series…” Change the “Series Overlap” to 100% and the “Gap Width” to 40%. You may not see the blue bar chart because the red bar chart will be in front of it. To fix this, go to the “Select Data Source” window and use the arrow to reposition the data series. This will place the blue bar chart in front of the red bar chart.
Step 5. Add the data labels.
The next step will include the data labels to the progress bar. We want to have the data labels aligned on the right. When you right-click the blue chart, you will get the data labels to be aligned to the left or the end of the bar. This does not get us to the data labels aligned on the right.
To do this, we need to right-click the red bar (not the blue bar) and click on “Add data labels.” This will all the data value for the progress bar, which is “1.”
Right-click on one of the data labels that has a “1” and select “Format Data Labels…” This will open a window where you will need to check the box next to “Value From Cells.” When prompted, select the values in the “percent_fully_vaccinated” column. This will add the percentage of the population that is fully vaccinated on the right-side of the bar chart. Additionally, uncheck the box next to “Value.” This will remove the value from the bar chart so that you will no longer see the “1.”
The chart should be updated to have the percentage of the population who are fully vaccinated aligned to the right-side of the bar chart.
Step 6. Modify the chart to improve the aesthetics.
Once you’ve added the data labels and aligned them on the right-side of the bar chart, you can start to edit the font color, bar colors, and delete the grid lines to emulate the chart in informationinbeautiful.net website.
I changed the background to a dark gray and the data labels to a white color. I also changed the font to Arial Narrow.
I only presented part of the figure here. But you can download and view the whole figure from my Drobox folder.
CONCLUSIONS
Using the vertical bar chart with progress bars allow us to emulate the figures generated by informationisbeautiful.net. I like these types of charts for data visualization because they provide some indication of progress. You can see that the United States is behind many nations when it comes to having the population fully vaccinated. This is much lower than the UAE and South Korea where 95.6% and 86.6% of the total population are fully vaccinated. Hopefully, you can use this exercise to help you develop similar charts for your data visualizations.
REFERENCES
Data was access using the Our World in Data COVID-19 site.
The data visualization that inspired this exercise was based on informationisbeautiful.net COVID-19 Coronavirus Data Dashboard.
The Excel file with the data used for this tutorial is available on my Dropbox folder.










{kind=link}