
INTRODUCTION
Between 1918 to 1919, the influenza pandemic (also known as the “Spanish Flu”) raged across the world and caused over 40 million deaths. Cities in the United States enacted nonpharmaceutical interventions (e.g., social distancing, shelter-in-place mandates) to reduce the transmission of the influenza pandemic, overall and peak attack rates, and the number of deaths. Some of the cities were successful in mitigating the calamity associated with the pandemic, but others were not. The experiences that these cities learned in the past yield important insight for policy makers today to tackle the current COVID-19 pandemic.
Markel and colleagues (2007) reported on the impact of nonpharmaceutical interventions enacted by cities in the United States and their effect that they had on mitigating the influenza pandemic of 1918 to 1919.[1] Briefly, their report highlights that cities that implemented these public health interventions early had greater delays in the time to reaching peak mortality, lower peak mortality rates, and lower total mortality.
We will recreate one of the figures (Figure 1c) in this manuscript using Excel and the data provided.
Figure from the study that we will recreate.[1]*
(*This figure is used for educational purposes only.)
DATA
Data for this tutorial come directly from the study’s Table 1. We will use the Public Health Response (days) in the X-axis and the Excess Pneumonia and Influenza Mortality rate (deaths per 100,000 population). You can download the data from the following link.
Step 1. Get the data
Download the data from this link. Data has been cleaned specifically for this tutorial.
Step 2. Insert a scatter plot chart
After downloading the data, open the Excel file. Look for the column that contains the Public health response time, days; this will be the data for the X-axis. Now, look for the column that contains the Excess pneumonia and influenza mortality, deaths / 100,000 population; this is the data for the Y-axis.
In Excel, insert the Scatter plot by selecting the Scatter option in the Charts tab.
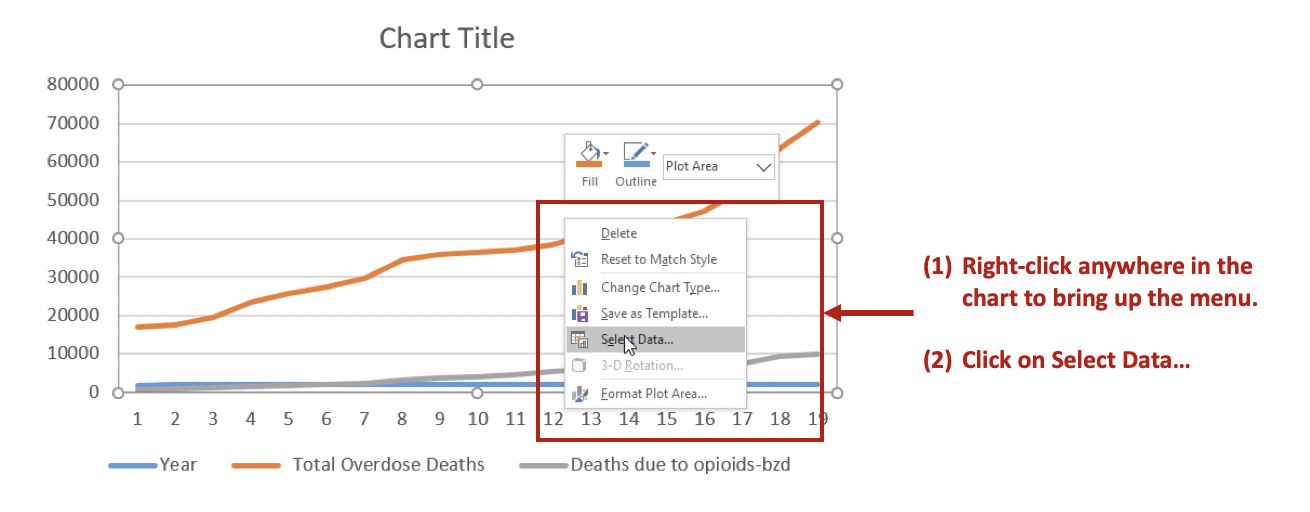
Step 3. Select the data for the Scatter plot
An empty figure will appear. Right-click in any area in the empty figure and you should be able to click on “Select Data”. From there, click on “Add” to add data and select the appropriate data for the X-axis values and the Y-axis values.
Clicking “OK” will generate a scatter plot of the excess deaths across the time the public health responded to the pandemic.
Step 5. Adjust the axes
First, we want to move the Y-axis so that it is flushed with the left side of the chart instead of intersecting at zero on the X-axis.
This will change the Y-axis position from its intersection on the X-axis = 0 to X-axis = -15.
Step 5. Change the color of the scatter
To finalize the scatter plot, change the color and size of the scatter.
FINAL SCATTER PLOT
Once all the adjustments have been made, we can add some data labels for some of the select cities, which were also highlighted with a different color.
CONCLUSION
After recreating the figure from the paper by Markel and colleagues,[1] it is clear that as public health response is delayed, there is a general trend for excess deaths due to the influenza pandemic to increase. Although other types of interventions occurred during this pandemic, the findings from Markel and colleague provides some empirical evidence that early public health measures have significant contributions in terms of mitigating the excess deaths due to the influenza pandemic. Policy makers can use the lessons from the past to inform them about the effectiveness of public health nonpharmaceutical interventions in delaying or reducing the mortality of the current COVID-19 pandemic.
REFERENCE
Markel H, Lipman HB, Navarro JA, et al. Nonpharmaceutical Interventions Implemented by US Cities During the 1918-1919 Influenza Pandemic. JAMA. 2007;298(6):644-654. doi:10.1001/jama.298.6.644












![Source: Flavored Tobacco Product Use Among Middle and High School Students—United States, 2014–2018. url: link [Accessed on 17 October 2019]](https://images.squarespace-cdn.com/content/v1/58cde3fcdb29d633eb688e9e/1571371774574-86F3QCME0HOTSY5M5VFP/Figure+1.png)



