
INTRODUCTION
As the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) continues around the world, data visualization experts have provided stunning visuals of the pandemic’s terrifying impact on public health. Several of these include a moving average metric that smooths the curves of the pandemic’s mortality data. Common moving averages presented by several of these visualizations include the 5-day average daily deaths and the 7-day average daily deaths. Information Is Beautiful presents mortality on a 7-day moving average while International SOS presents the average daily deaths as 5-day moving averages.
Figure 1. 7-day moving average daily deaths by Information Is Beautiful (Last updated on 19 May 2020).
MOTIVATING EXAMPLE
In this article, we will replicate the 5-day and 7-day (moving) average daily deaths due to SARS-CoV-2 using data from the European Centre for Disease Control and Prevention (ECDC)1 or from the Our World in Data’s GitHub site.2 Due to the changing nature of SARS-CoV-2 data, this exercise will have used data that would ultimately be updated in the future. Please visit the ECDC or the Our World in Data site to download the most recent SARS-CoV-2 data.
We will download data from the Our World in Data’s GitHub site and then use Excel to recreate this plot for the United States (US).
Step 1. Download data from the OWID Covid-19 GitHub site
You can download the raw data for all the countries from the OWID’s site here. However, you can also download the cleaned data for this article (parsed for the United States) from my Dropbox folder here (I cleaned the data and prepared them for use in Excel).
The data has the following format:

We are interested in the new_deaths column, which is the number of new confirmed deaths by day. The moving average will estimate the average daily deaths across either 5-day or 7-day time periods.
Step 2. Add columns for the 5-day and 7-day moving average.
When you load the data into Excel, you will need to create two columns; one for the 5-day average daily death and another for the 7-day average daily deaths. I used MAD_5 for 5-day moving average daily deaths and MAD_7 for 7-day moving average daily deaths.

Step 3. Activate the Analysis ToolPak
Excel has a tool that will perform simple analysis; however, you may need to activate this if it is not on the ribbon.
Once the Options selection has been selected, you can navigate to the Add-in option and open the window to select the Analysis ToolPak. You only need the Analysis ToolPak for this exercise, but it is a good idea to explore the other tools available (e.g., Solver).
Step 4. Estimate the moving average
Once the Analysis ToolPak is activated, return to your main worksheet with the new data columns. Start by selecting the cell where you want the first moving average value to be calculated. Then select the Data Analysis add-in. This will open a window with different Analysis Tools. Select the Moving Average tool.
Once you click “Ok,” you will be asked for several elements to calculate the moving average. You will need to select the Input Range, the number of days needed for calculating the moving average, and the Output Range. After selecting the appropriate information, you can click “Ok” to generate the moving average. Do these steps for the 5-Day and 7-Day moving average daily deaths.
Step 5. Generate the line graph
Now that the average daily deaths are calculated for 5-day and 7-day moving averages, you can generate a line graph that resembles Figure 1.
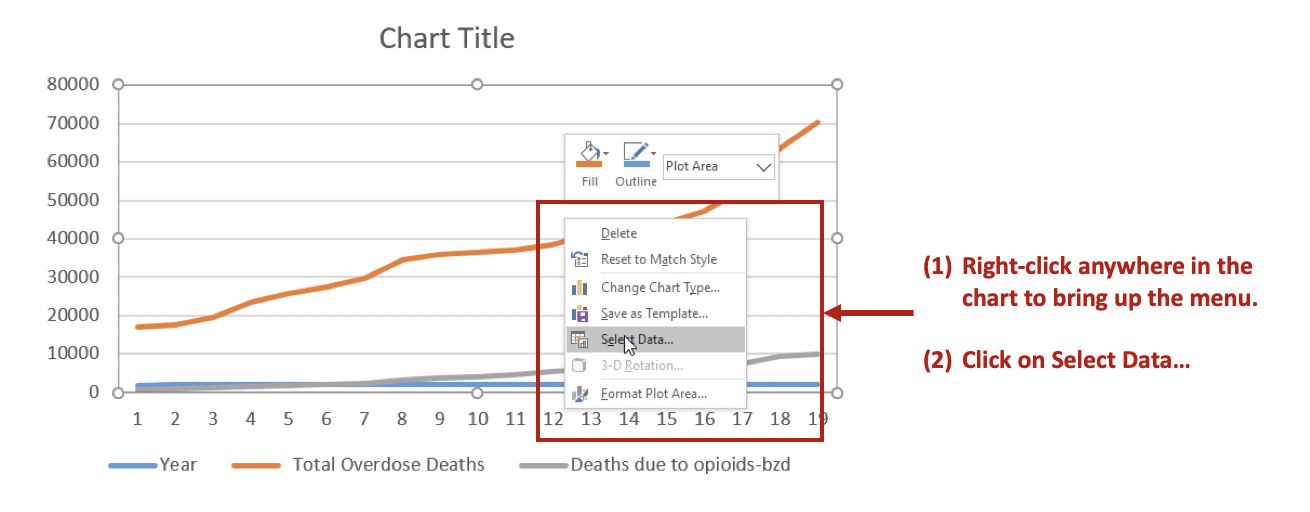
Insert a line graph onto the Excel worksheet. Right click on any empty area of the line graph; this will open up the edit options.
You can make edits to the figure like entering the data to create the line graph. The Series values is the set of numbers that you calculated for the 5-day average daily deaths.
Once you have selected the data for the Series values, you can edit the x-axis label. Currently, the x-axis defaults to a sequence of 1, 2, 3, …, n. You want this to reflect the dates which are on the B column. Click on Edit and select the dates on the B column to properly relabel the x-axis.
This will generate the first line graph with the 5-day average daily deaths visualization.
Step 6. Finalize the figure
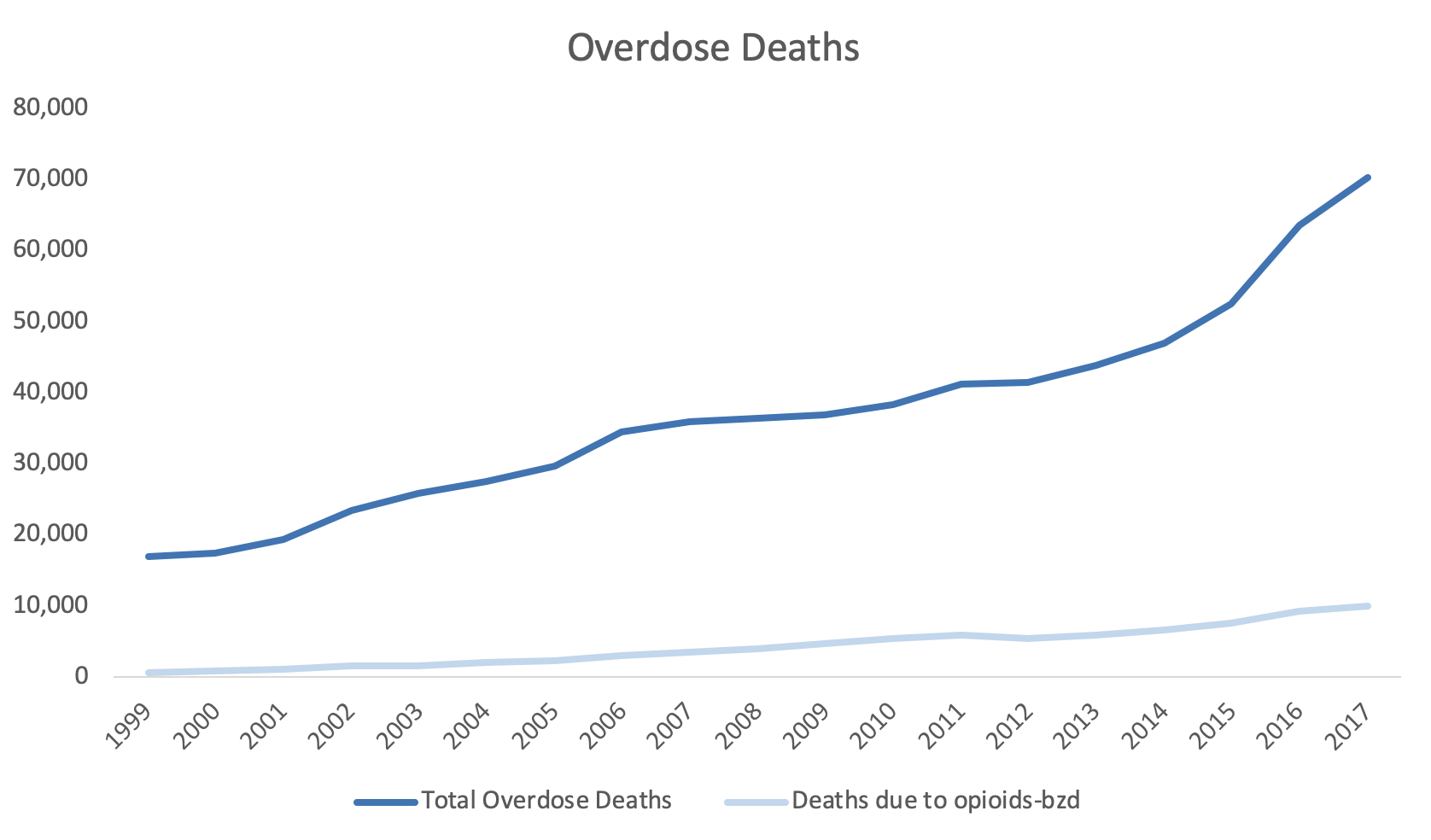
After adding the 5-day average daily deaths, go ahead and repeat these steps for the 7-day average daily deaths. Using Excel’s format feature, you can make changes to the figure’s size, height, and colors. To replicate Figure 1, you will need to change the y-axis to a logarithmic scale.
After changing the scale on the y-axis and adding the 7-day average daily deaths, you should get a figure similar to the one below.
You can also present this without the logarithmic scale.
CONCLUSIONS
The moving average daily deaths smooths the line plots and provide a trend that is easy to understand and interpret. The major difference between these moving average plots and the mortality curves (see previous blog) is the ability to see the decline in daily deaths. The average daily deaths curve allows us to see the decline in the amount of deaths on a moving average. Mortality curves don’t do that since they are based on the total amount of deaths. Despite the differences in plots, both the moving average daily deaths and mortality curves provide critical visual information about the current SARS-CoV-2 trends.
You can download the data and complete exercise here.
REFERENCES
European Centre for Disease Control and Prevention. Download today’s data on the geographic distribution of COVID-19 cases worldwide. European Centre for Disease Prevention and Control. Published April 18, 2020. Accessed May 19, 2020. https://www.ecdc.europa.eu/en/publications-data/download-todays-data-geographic-distribution-covid-19-cases-worldwide
Our World in Data. GitHub: Owid/Covid-19-Data. Our World in Data; 2020. Accessed May 19, 2020. https://github.com/owid/covid-19-data











![Source: Flavored Tobacco Product Use Among Middle and High School Students—United States, 2014–2018. url: link [Accessed on 17 October 2019]](https://images.squarespace-cdn.com/content/v1/58cde3fcdb29d633eb688e9e/1571371774574-86F3QCME0HOTSY5M5VFP/Figure+1.png)




![Source: Duyckinick, Evert A. Portrait Gallery of Eminent Men and Women in Europe and America. New York: Johnson, Wilson & Company, 1873. [Link]](https://images.squarespace-cdn.com/content/v1/58cde3fcdb29d633eb688e9e/1568496739332-8DTOJ4ICBOXGQYP8UQZQ/1024px-Florence_Nightingale_three_quarter_length.jpg)
![Source: Mortality of the British Army, At Home, At Home and Abroad, and During the Russian War, As Compared with the Mortality of the Civil Population in England. 1858. Harrison and Sons, St. Martin's Lane. [Link] [Accessed September 11, 2019].](https://images.squarespace-cdn.com/content/v1/58cde3fcdb29d633eb688e9e/1568496963927-4OTDFW5EDM6WK2X8OD1C/Figure+3+-+table.png)
{kind=link}
{kind=link}