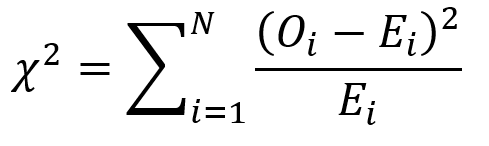BACKGROUND
Inspecting your data is an important part of data analysis preparation. Data, like all things, should behave according to some reasonable expectation. For example, if we randomly sampled a group of people in the U.S., we would reasonably expect to get 50% males and 50% females. Similarly, if we examined the age distribution of this sample, we would expect to have a normal distribution.
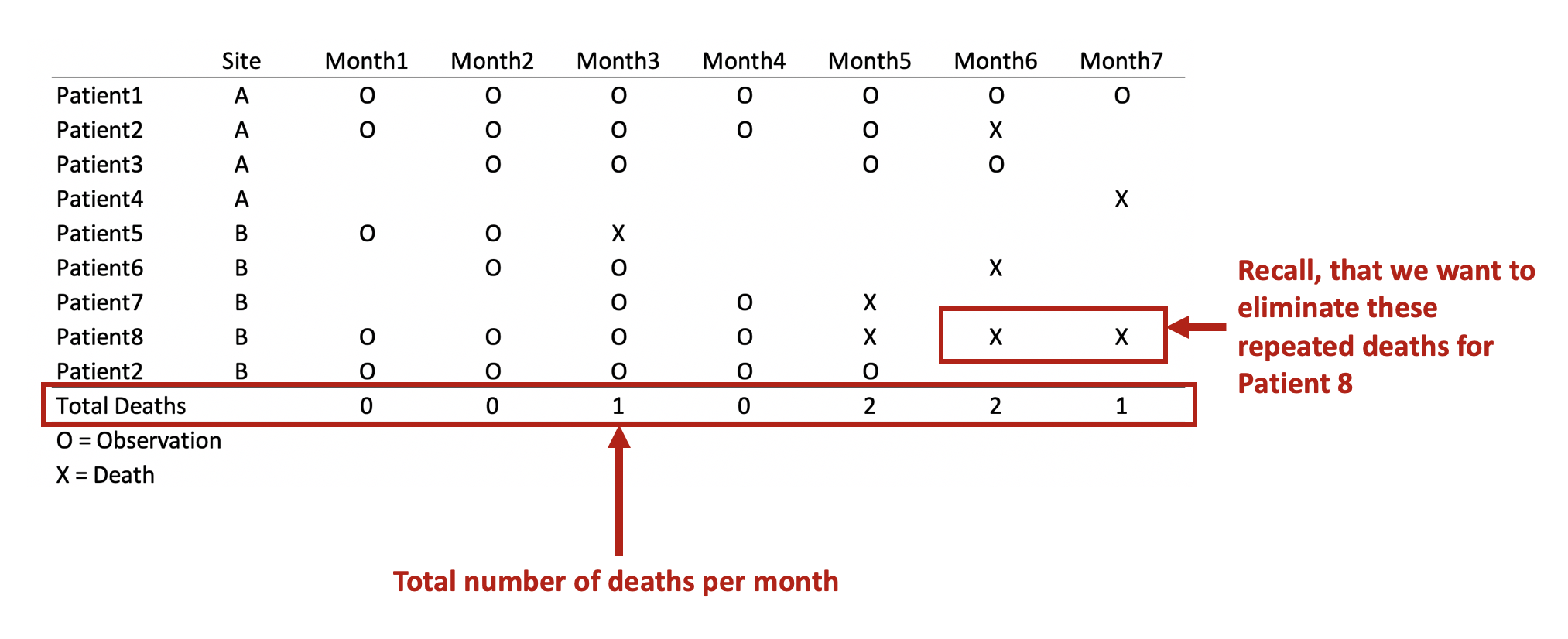
At the macro level, we may only be interested if the mean and standard deviations are representative of the population distribution. Since we sample from the population (randomly), we would expect to get similar means (and medians). This can be accomplished using simple Excel functions (or commands in statistical packages) to generate a descriptive summary. Table 1 describes the summary statistics for the total fat consumed by a sample of 8,327 responders to the National Health and Nutrition Examination Survey (NHANES) survey.

We can see that the mean and the median are different, which is an indicator that the distribution is not normal. However, we may be interested in learning more about the distribution or behavior of this variable. Are there any outliers? How skewed is the distribution?
HISTOGRAMS
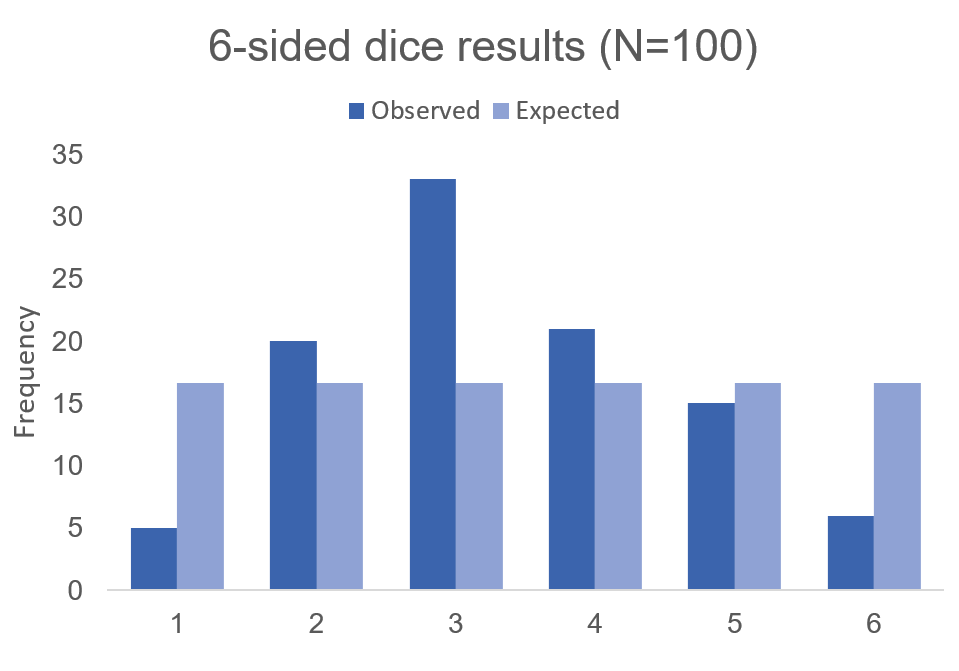
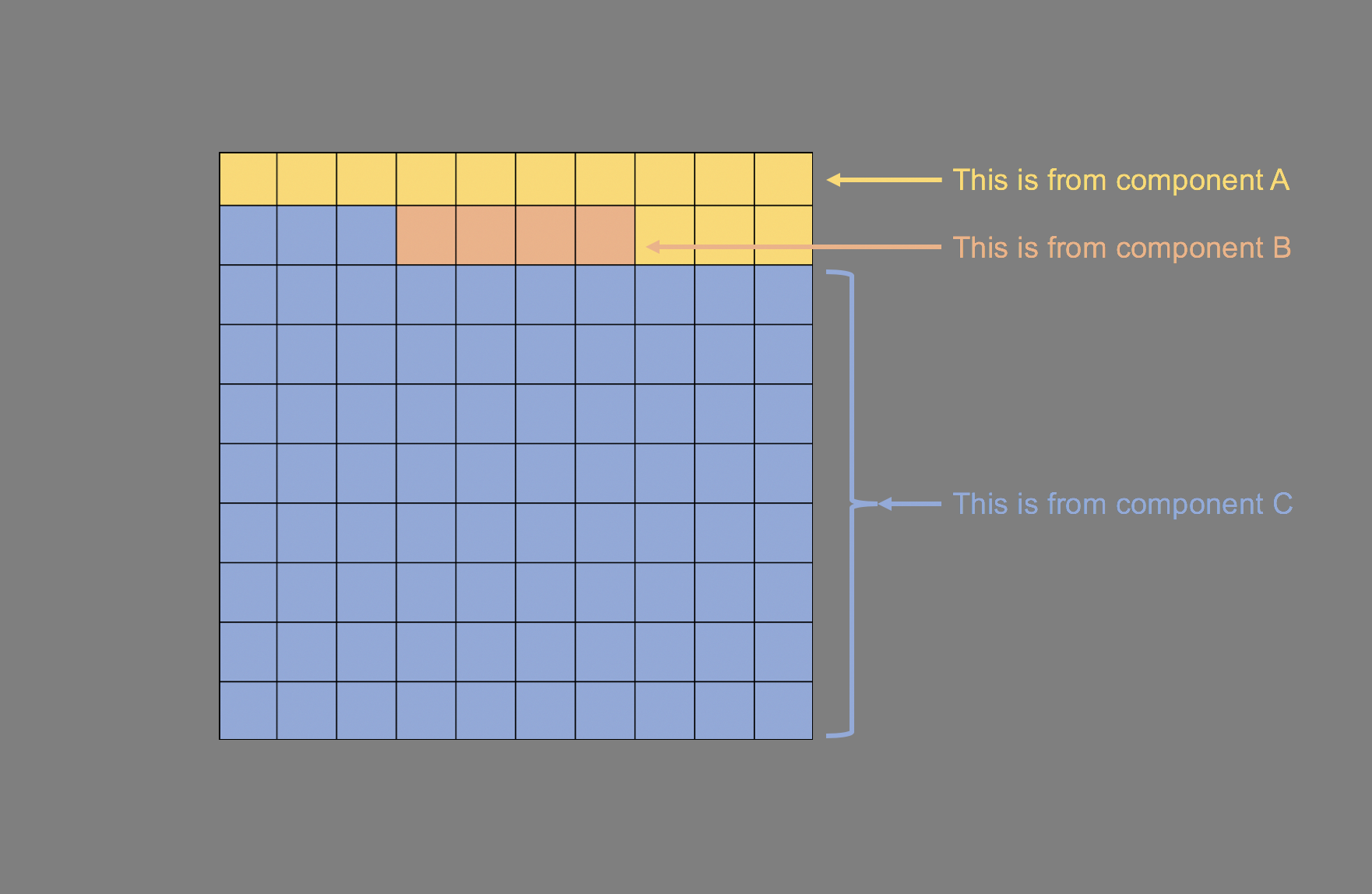
To visualize this, we will need to generate a histogram. A histogram is a visual representation (bars) of the distribution of data (usually continuous). It uses spacings called “bins” to count the number of times a value falls into that bin. A histogram looks like a bar chart, but the key difference is that in the histogram the adjacent bars are touching each other rather than having a space between them. Another difference is that histograms plot the frequency (or density) of a value or a range of values for a continuous data type; whereas, bar charts plot the count of a discrete data type (Figure 1).
Figure 1. Comparisons between histogram and bar chart.
Keep in mind that the number of bins for histograms should be just enough to make out the distribution and not too small to be too much information. This is Grice’s maxim of quantity where data are presented in an informative manner without overwhelming the audience with too much information.[1] Creating smaller bins to increase the resolution of the histogram is unnecessary when all you want is a general visualization of the data’s distribution.
MOTIVATING EXAMPLE
We will use data from the NHANES survey (2015-2016) to generate a histogram in Excel. The data can be downloaded from my Dropbox folder here. I cleaned the file so that all missing data were dropped. In total, there are three variables:
· seqn = subject identifier
· drqsdiet = special diet (Yes/No/Don’t know)
· dr1ttfat = amount of total fat (gm) consumed
We will create a histogram to visualize the distribution of total fat consumed by the subjects. To start, let’s select the data and insert a histogram chart from the Insert Tab.
A histogram will be inserted near where your data are located on the worksheet. Excel automatically selects the bin sizes for you. But you can customize this to your needs.

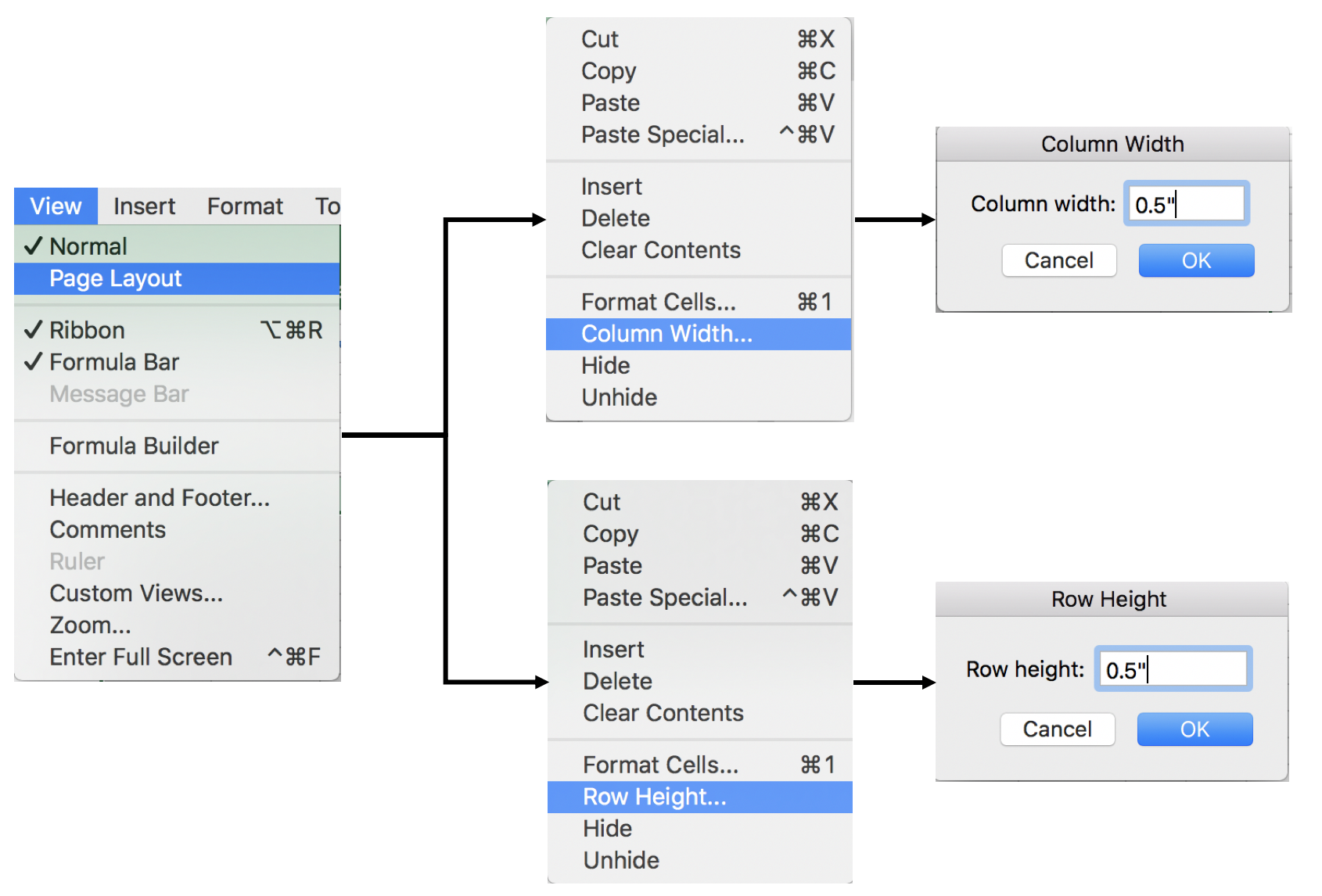
Right click anywhere x-axis and select Format Axis. You should see a column on the right side appear with options to modify the bin sizes.
You can modify the bin width, number of bins, the overflow bin, and underflow bin.
The bin width can be larger or smaller depending on how much resolution you want. You should balance this out with the appropriate number of bins you want to show. According Grice’s maxim of quantity, you don’t want to overwhelm your audience. In Excel, you can only modify either the bin width or the number of bins; never both.
The overflow bin indicates what the last bin should be. If anything is over the overflow bin value (X), then Excel will collapse those frequencies into that last bin. For example, if I wanted the overflow bin to be 137 grams or greater, I enter “137” into the overflow bin field. You can do the same thing on the other end of the x-axis with the underflow bin value.
Once you’ve figure out how to change the number of bins, let’s change the number of bins from 66 to 100, 75, 50, and 25 to observe how the histogram changes.
Notice that the histogram with a bin size of 100 is really fine whereas the bin size of 25 is blocky. We can tell from all of these figures that there is a right skew to the distribution due to a few outliers. There are 3 subjects who consume more than 400 grams of total fat compared to 19 subjects who consume between 300 and 399 grams of total fat. The higher resolution doesn’t really help us determine that the total fat consumption is right skewed compared to the figures with bin sizes of 75 and 50. If I were presenting to an audience or publishing an appendix, I would select either the figure with a bin size of 75 or 50. These two histograms illustrate the peak at the mean and the right-skewed distribution without violating Grice’s maxim of quantity. However, different situations will require you to make different choices, so I encourage you to explore the design features on Excels’ histogram.
STEM-AND-LEAF HISTOGRAM
The stem-and-leaf display is an alternative histogram that uses the prefix of number to assign positions into the bins. The following figure is a randomly selected number of subjects from our NHANES data. The first subject consumed 14 grams of total fat which is indicated by the 1* | 4. The 1* represents the first digit of “14” and the “|” separates the next digit. Similarly, there is one subject who consumed 22 grams of total fat indicated by the 2* | 2 and another subject consumed 24 grams of total fat (2* | 4).

CONCLUSIONS
Histograms are a great visualization tool to quickly check whether your continuous data are normally distributed. You can identify whether the mean is close to the median or whether there are left or right skewness to your data. Moreover, you can change the bin sizes of a histogram to become more refined or less so. But according to Grice’s maxim of quantity, it is best to present enough data that will get the information across to your audience without overwhelming them with unnecessary details.
REFERENCES
Grice, H. P. Logic and Conversation. In Cole P. and Morgan J. (Eds), Syntax and Semantics: Vol 3, Speech Acts. Academic Press, New York, pp.43-58, 1975.