BACKGROUND
A heat map is a data visualization tool that uses positioning and coloring to identify clusters and correlations in multivariable analysis. The most common type of heat map is a 2 x 2 matrix, where two variables are examined using the rows and columns (R x C) positions on a matrix. A heat map matrix helps us identify any patterns or similarities across the different dimensions. In a heat map, color is critical in denoting degrees of change. (Please see refer to the past blog on colors.)
For example, we can see the changes in opioid overdose rates across time for each state (Figure 1). As the rates increase, the cells are darker (indicated by the legend). All the states experience an increase in opioid overdose deaths, but State 1 is experiencing it faster than States 2 and 3.
In this tutorial, we will perform two methods to create heat maps. The first method will use the built in Excel conditional formatting rules and the second method will use VBA macros.
Figure 1. Heat map matrix.

MOTIVATING EXAMPLE
We will continue to use the state-level drug overdose mortality data from the CDC.
https://www.cdc.gov/drugoverdose/data/statedeaths.html
Mortality rate is presented as the number of deaths per 100,000 population.
In this tutorial, we will develop a heat map using opioid overdose mortality from 2013 to 2016.
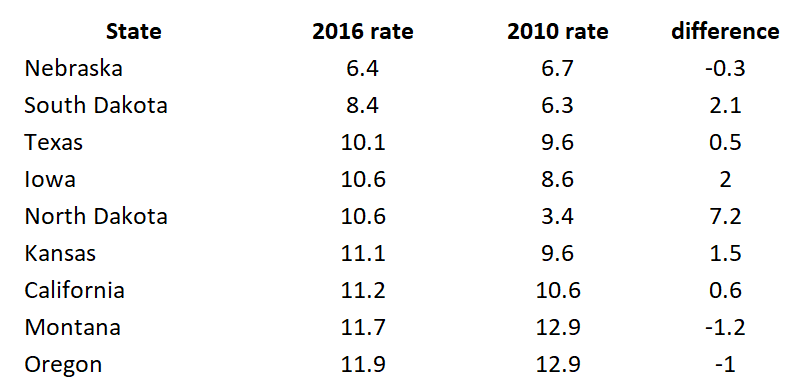
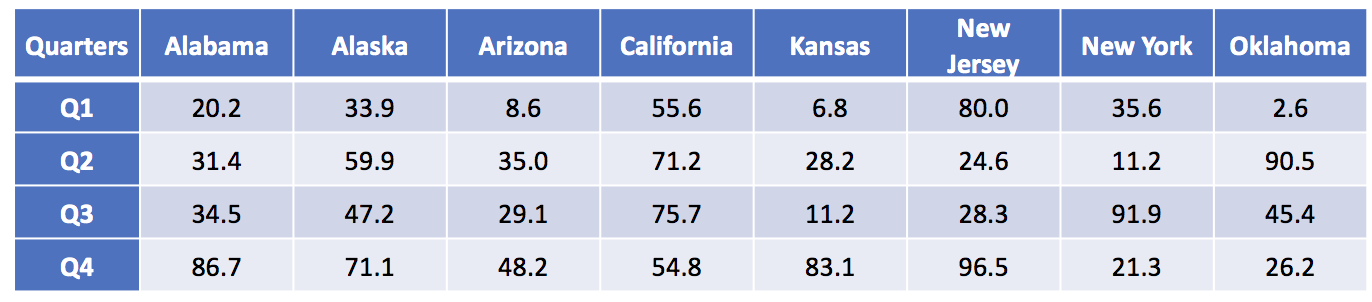
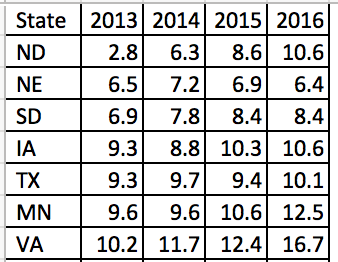
The data setup in Excel has State indicators as the rows and time indicators as the columns. We are visualizing the change in opioid overdose mortality from 2013 to 2016 for each state. Figure 2 illustrates the data structure for the first seven states.
Figure 2. Data structure for the first seven states.
METHOD 1: CONDITIONAL FORMATTING RULES
Excel has a convenient tool that allow us to use conditional formatting to shade our heat map matrix.
Step 1: First highlight all the data.
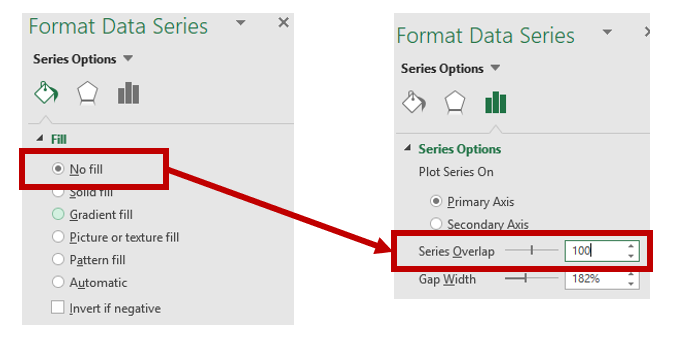
Step 2: In the Excel Ribbon, select Conditional formatting and then New.

Step 3: Select “Format all cells based on their values” and change the Format Style to “3-Color scale.” Change the color to the different shades you are interested in using. (In this example, we used a blue base with varying degrees of shading.) Select percentile and then click “Ok.” The percentile will use the Median for each column to distinguish the middle category for the rates of opioid overdose mortality for each state.

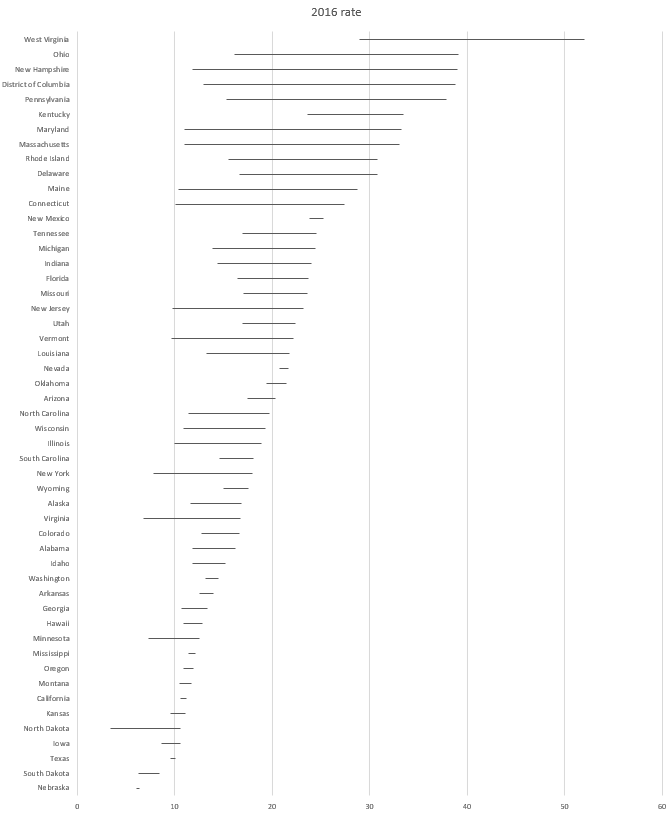
Step 4: Visually inspect the results. If there are no apparent pattern in the heat map, we will need to sort the rate of opioid overdose mortality for 2016 in descending order.
The heat map should look like the following:

There is a pattern emerging in regards to the rate of opioid overdose mortality across the different states. West Virginia has the highest opioid overdose mortality rate in 2016, but they also appear to have the highest from 2013 to 2015. The dark cell in 2016 indicates that West Virginia has exceeded the 50 deaths per 1000 population incidence rate. Other states also have high rates of opioid overdose mortality across 2013 to 2016, which continued to increase. The 2013 column is clearly lighter indicating that the opioid overdose mortality has increased over time up to the available data in 2016.
Step 5: We can improve this heat map by removing the numbers, which can be distracting. We need to select all the data and format the cells. Select only the numeric data and then format the number. Use the “Custom” category and enter the following: "";"";"";"". This will change the number values so that it doesn’t show in the cells.

Step 6: Change the column width and row height so that you have a nice square-like matrix for the final result. We used a column width of 5 and a row height of 30. (Only the first fifteen states are shown.)
The heat map can be used to quickly identify states with the highest opioid overdose mortality and the trends across time. The states with the highest rates of opioid overdose mortality are clustered at the top while the states with the lowest rates are clustered at the bottom.
We could also arrange this into regions of the US to further stratify the results (not shown).
METHOD 2: USING VBA MACROS FOR CONDITIONAL FORMATTING OF MORE THAN 3 CATEGORIES
Excel only allows us to choose up to 3-Color scales. If we wanted to use more than 3 color categories, we will need to use VBA macros.
But before we do, we need to think about the colors for the scales. Since we have more than 3 categories, we will need to figure out how to divide the colors.
COLOR CODES
We will need to determine the base color for our heat map. In this example, we will use a blue base-color and change the shading using the RGB color values. RGB colors are based on a system using a combination of three base colors (red, green, and blue) that can be used to change the intensity of the color from a range between 0 and 250. An example of an RGC color table can be found in the following site.
For this example, we used the following RGB color values where dark-navy denotes high rates of opioid overdose mortality (50 or more per 1000 population). However, you can change the values of these colors however you like.

We will continue to use the blue color base and change the gradient using the RGB values.
VISUAL BASIC FOR APPLICATION (VBA) MACRO
The VBA macro comes from the site Excel For Beginners and written by Kristoff deCunha. We used the VBA code on the site, but modified it for this tutorial.
The VBA code is written in a way where any changes in the values will automatically update the color of the cell. Additionally, the code also sorts the 2016 opioid overdose mortality rate in descending order, adds thin-white continuous borders around the cells, and changes the font to Times New Roman.
Here are the VBA macros used for Method 2.
Macro 1 changes the font to Times New Roman.
‘Macro1
Sub ChangeFont()
Dim rng As Range
Set rng = Range("J1:N52")
With rng.Font
.Name = "Times New Roman"
.Size = 12
.Strikethrough = False
.Superscript = False
.Subscript = False
.OutlineFont = False
.Shadow = False
.Underline = xlUnderlineStyleNone
.ThemeColor = xlThemeColorLight1
.TintAndShade = 0
.ThemeFont = xlThemeFontNone
End With
End Sub
Macro 2 changes the cell shading to the 6-Color scale (blue-base)
‘Macro2
Sub ChangeCellColor()
Dim rng As Range
Dim oCell As Range
Set rng = Range("K2:N52")
For Each oCell In rng
Select Case oCell.Value
Case 50 To 100
oCell.Interior.Color = RGB(37, 54, 97)
oCell.Font.Bold = True
oCell.Font.Name = "Times New Roman"
oCell.HorizontalAlignment = xlCenter
Case 40 To 49.999
oCell.Interior.Color = RGB(56, 83, 145)
oCell.Font.Bold = True
oCell.Font.Name = "Times New Roman"
oCell.HorizontalAlignment = xlCenter
Case 30 To 39.999
oCell.Interior.Color = RGB(147, 168, 215)
oCell.Font.Bold = True
oCell.Font.Name = "Times New Roman"
oCell.HorizontalAlignment = xlCenter
Case 20 To 29.999
oCell.Interior.Color = RGB(183, 198, 228)
oCell.Font.Bold = True
oCell.Font.Name = "Times New Roman"
oCell.HorizontalAlignment = xlCenter
Case 10 To 19.999
oCell.Interior.Color = RGB(218, 225, 240)
oCell.Font.Bold = True
oCell.Font.Name = "Times New Roman"
oCell.HorizontalAlignment = xlCenter
Case 0 To 9.999
oCell.Interior.Color = RGB(230, 237, 253)
oCell.Font.Bold = True
oCell.Font.Name = "Times New Roman"
oCell.HorizontalAlignment = xlCenter
Case Else
oCell.Interior.ColorIndex = xlNone
End Select
Next oCell
End Sub
Macro 3 sorts the 2016 opioid overdose mortality rates in descending order.
‘Macro3
Sub SortColumn()
Dim DataRange As Range
Dim keyRange As Range
Set DataRange = Range("J1:N52")
Set keyRange = Range("N1")
DataRange.Sort Key1:=keyRange, Order1:=xlDescending
End Sub
Macro 4 hides the font from the heat map.
‘Macro4
Sub HideFont()
Dim rng As Range
Dim oCell As Range
Set rng = Range("K2:N52")
For Each oCell In rng
oCell.Font.Color = oCell.Interior.Color
Next oCell
End Sub
Macro 5 creates thick white borders for each cell in the table.
‘Macro5
Sub WhiteOutlineCells()
Dim rng As Range
Set rng = Range("J1:N52")
With rng.Borders
.LineStyle = xlContinuous
.Color = vbWhite
.Weight = xlThick
End With
End Sub
INSERTING DATA AND RUNNING MACRO
The five macros are assigned to a button in the Excel Macro-Enabled Workbook. Pressing the button will perform the task of creating a 6-Color scale heat map. Download the Excel Macro-Enabled Workbook here. This file will have the raw data and the macro-enabled worksheet for you to create a heat map.
Step 1: Copy the raw data from the “combined” worksheet.

Step 2: Paste it in the worksheet “heatmap_2” starting on cell "J1".

Step 3: Then press the “PressStart” button to run the macros. Your final heat map should look like the following:
Compare the heat map from Method 1 (3-Color scale) to the one generated by Method 2 (6-Color scale). The heat map with the 6-Color scale has a lighter pattern compared to the 3-Color scale heat map. The differences are dramatic. Depending on the granularity of the heat map you want, either one of these color scales would be fine. However, Method 2 requires some VBA coding.
* Not all states shown.
Conclusions
Heat maps allow us to observe patterns in the data. In our example, we notice that West Virginia has a high rate of opioid overdose mortality indicated by the clustering of dark cells from 2013 to 2016. Other states had similar patterns as West Virginia. Using heat maps provides a quick and easy interpretation of the changes in opioid overdose mortality across time and the states that are clustered together that have high rates of opioid overdose mortality.
REFERENCES
I used the following websites to help develop this tutorial.
Conditional formatting with more than 3 categories:
https://sites.google.com/site/excelforbeginners/Home/vba-codes/conditional-formatting-more-than-3-criterias
Changing the RGB color codes:
https://analysistabs.com/excel-vba/change-background-color-of-cell-range/
https://www.w3schools.com/colors/colors_rgb.asp
Excel color palette library:
http://dmcritchie.mvps.org/excel/colors.htm
Excellent site for VBA coding:
https://www.excel-easy.com/vba.html