INTRODUCTION
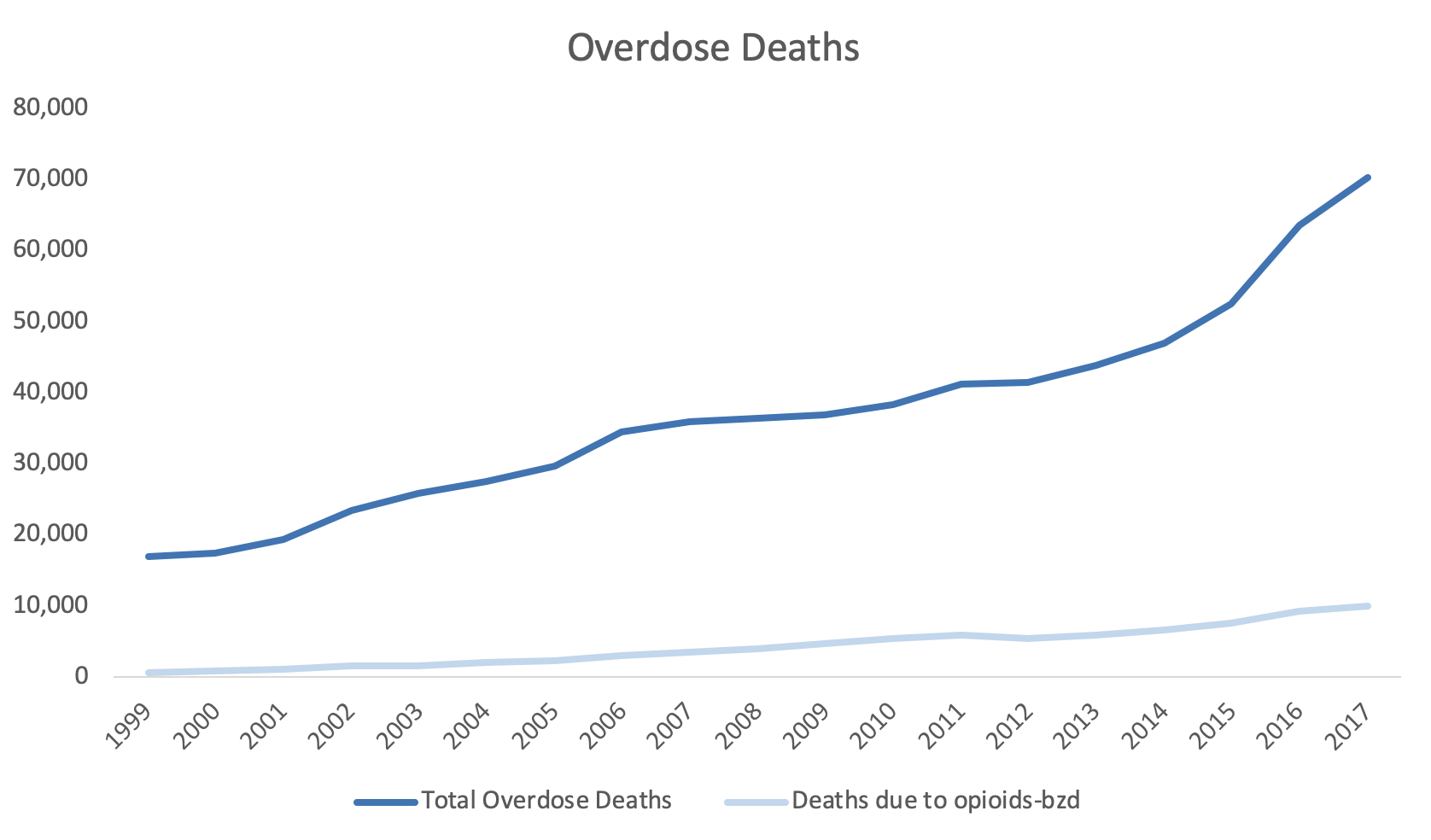
A recent paper by Wang and colleagues reported that patients with recent diagnosis of substance use disorder (SUD) had a greater risk for COVID-19.[1] The adjusted odds ratio was 8.699 with a 95% confidence interval (CI) of 8.411 to 8.997). Patients with opioid use disorder (OUD) were at the greatest risk.
The authors used a forest plot to summarize their findings (Figure 1). A forest plot is a diagram that displays the measurement of interest (e.g., odds ratio) with horizontal error bars to represent the 95% CI for several variables, which are aligned on the Y-axis. Forest plots are common in pair-wise meta-analysis where multiple studies are used to describe the effect size of the treatment versus the comparator group. Studies are arranged along the vertical axis and the odds ratio with 95% CI are displayed next to the studies. This allows the readers to see the effect size (e.g., odds ratio) and the uncertainty surrounding each study (or variable) in the meta-analysis.
Wang and colleague used this method to illustrate the odds of developing COVID-19 for different types of substance use disorders diagnosis along with their uncertainties. It’s an effective way to illustrate how much of a risk each SUD diagnosis category is associated with developing COVID-19.
Figure 1. Forest from the study that we will recreate.[1]*
(*This figure is used for educational purposes only.)
DATA
We will use the study by Wang and colleagues[1] to recreate their forest plot using Excel. Although it is much easier to code this in Stata or R, for the purpose of this tutorial, we will use Excel.
Step 1. Get the data
Since there are a few data points, we can enter these directly into an Excel spreadsheet. There are some nuances that we will need to consider when plotting these data points. A template is available to assist you with entering the data correctly. I have provided an illustration below for how you should set up your data in Excel. (You can download this template here.)
Once the data have been entered into Excel, we can begin to generate the figure.
Step 2. Insert a scatter plot chart
In the tab, select Insert and then select the scatter plot drop down. You will see a series of different scatter plots to choose from. Select the one that says “Scatter.”
Step 3. Select the data for the Scatter plot
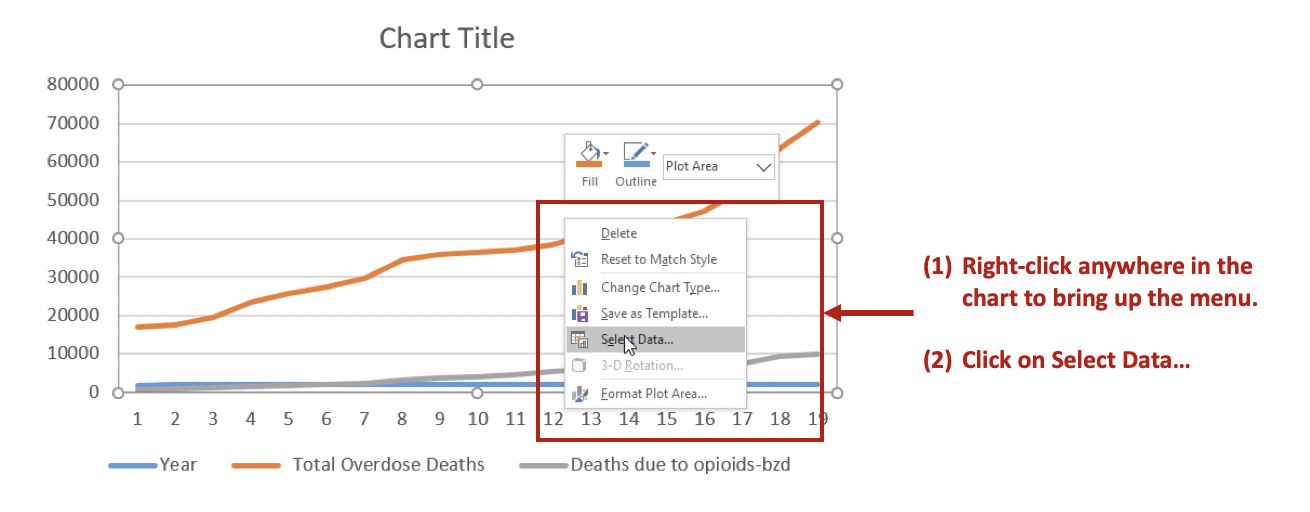
Right-click in the empty chart area to select the data. Select the Add button to select the data of interest.
In the Series name field, enter “data.” Then for the Series X-values, select the values in the Odds ratio column. For the Series Y-values, select the value in the Y position column as indicated in the figure.
Your scatter should appear on the Chart area.

Step 4. Add labels on the Y-axis
We want to have the labels on the Y-axis indicating what SUD diagnosis was associated with an increased odd for developing COVID-19. Similar to the previous data entry, we will begin by Right-clicking on the Chart Area and selecting Add data. For the X values, select the values in the Y Label position column. For the Y values, select the values in the Y position column as indicated below. Once you select the data, the Chart Area will update with the orange scatter points on the Y-axis.
Right-click the orange scatter points on the Y-axis. Then select the “Add Data Labels” to include data labels to the orange scatter points.
Right click on the data labels and click on the Format Data Series. Make sure to check the box next to Series Name and uncheck the box next to Y value. Check the box next to the Values From Cell, click on the Select Range box to open another window where you can select the data labels. Select all the SUD diagnosis for this data range in the Select Data Label Range field.
Data labels for the SUD diagnoses will appear on the right side of the scatter on the Y-axis. Next, we will reposition the SUD diagnoses labels to the left of the Y-axis. Right-click on the orange scatter and then select “None” in the Marker options to remove the scatter on the Y-axis. Then Right-click on the Y-axis value and then enter the “Delete” key on your keyboard. This will remove the labels on the Y-axis (e.g., 1, 2, 3, 4, 5, 6, and 7). All that should remain are the SUD diagnoses labels. To reposition these, right-click on the SUD diagnoses labels and then check the “Left” option in the Label Position field.
This will reposition the SUD diagnoses labels to the left of the Y-axis.
Step 5. Add the error bars for the 95% CI
Next, we will include the horizontal error bars to represent the 95% CI. Click anywhere in the Chart Area and the Chart Design tab will become available in the Ribbon. Select “Add Chart Element” dropdown arrow to open up the available options and select “Error Bars.” Select the “Standard Errors” to display both the horizontal and vertical error bars around the scatter points on the chart.
We want to keep the horizontal error bars, so we need to delete the vertical error bars. Select the vertical error bars and then hit the “Delete” key on your keyboard. This will remove the vertical error bars and leave you with only the horizontal error bars. Next, you want to adjust the horizontal error bars. Currently, this is not displaying the correct 95% CI. Right-click on the horizontal error bar and select the “Format Error Bars…” option.
Select the “Specify Value” box next to the Custom option for the error bars. We will determine what Excel plots for the 95% CIs. For the “Positive Error Value” select the values under the “UL – OR” column. Similarly, for the “Negative Error Value” select the values under the “LL – OR” column.
The appropriate error bars now reflect the 95% CIs from the figure generated by Wang and colleagues.
Step 6. Adding the null line at Odds Ratio = 1
To add the vertical line that cross where the odds ratio (OR) is equal to 1, we need to use the column “Null position.” Right-click anywhere on the Chart Area and click on “Select Data. This opens up the data menu. Click on “Add Data.” Then follow the instructions to select values in the Null Position column for the Series X values box and the values in the Y position column for the values in the Series Y values box. We’ll name the “null” data series since this is where the odds ratio is equal to 1.
Right click on the scatter and select “Change Series Chart Type” to open the window where you can select different chart styles. For the Null data series (e.g., odds ratio is equal to 1), change the Chart Type from “Scatter” to “Scatter with Straight Lines.” This will generate a straight vertical line along the values where the odds ratio is equal to 1.
Right-click on the scatter point along the straight line and Format Data Series…; then remove the marker by selection None under the Marker Options.
Step 7. Modify the chart presentation
At this stage, most of the necessary steps to include the forest plot is complete. Final steps involve changing the colors, adjusting the length of the Y-axis, and removing the gridlines. I also included the odds ratio (OR) and 95% CI by the forest plot on the right side by enter each value into the corresponding cells in Excel. I also added a blue line at the top of the forest plot and some text boxes for the labels corresponding to the SUD diagnoses and the odds ratios with their 95% confidence intervals.
CONCLUSIONS
The final Excel forest plot is similar to the one generated by Wang and colleagues.1 I opted to leave out the P-values since they were all significant and did not include any additional information to the chart. Some additional modifications included the use of a red dotted line for where the odds ratio (OR) is equal to 1 and the use of a blue top border to separate the labels for the chart columns.
Forest plots are great when you want to show the impact each variable has on a particular outcome. In our example, each of the different SUD diagnosis has an impact on the odds of developing COVID-19. From the forest plot, it is easy to identify OUD as having the greatest odds of developing COVID-19.
One additional thing that we can do is order this from the highest odds ratio to the lowest odds ratio, which will give us a better way to compare relative strengths across the different SUD diagnosis categories (see below).
You can download the Excel file for this exercise here.
REFERENCES
Wang QQ, Kaelber DC, Xu R, Volkow ND. COVID-19 risk and outcomes in patients with substance use disorders: analyses from electronic health records in the United States. Mol Psychiatry. Published online September 14, 2020:1-10. doi:10.1038/s41380-020-00880-7.