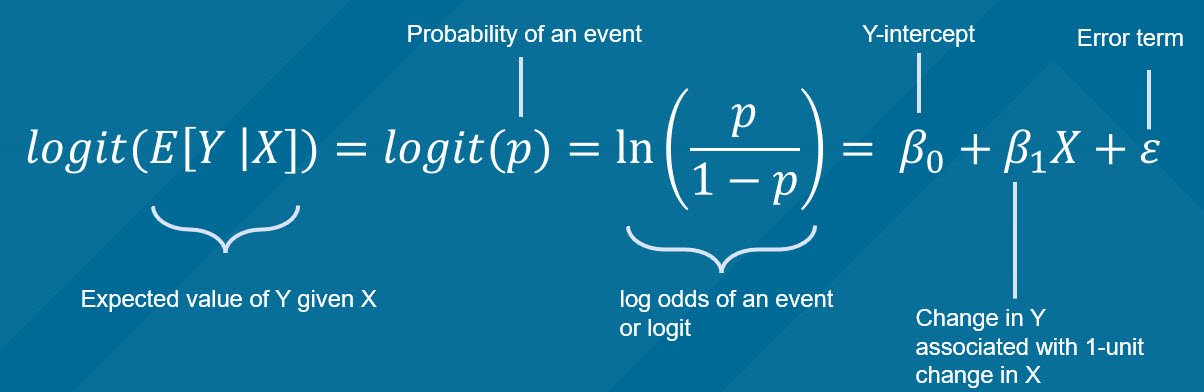In a previous tutorial, I discussed how to perform logistic regression using R. I wrote a follow-up tutorial on how to conduct goodness of fit tests for logistic regression models in R and posted it on RPubs. The R Markdown code is available on my Github site.
I’ve learned how to assess model fit using Pearson correlations, deviance, and modified Hosmer-Lemeshow Goodness Of Fit (GOF) tests. I think these are important tools when assessing the fit of a logistic regression model. However, I wanted to focus on the HL GOF tests for this tutorial because there are a lot of nuances that I learned and wanted to share.
Additionally, I added the usefulness of visualizing whether the model over- or under-predicts the actual observed data using the calibration plot in R.