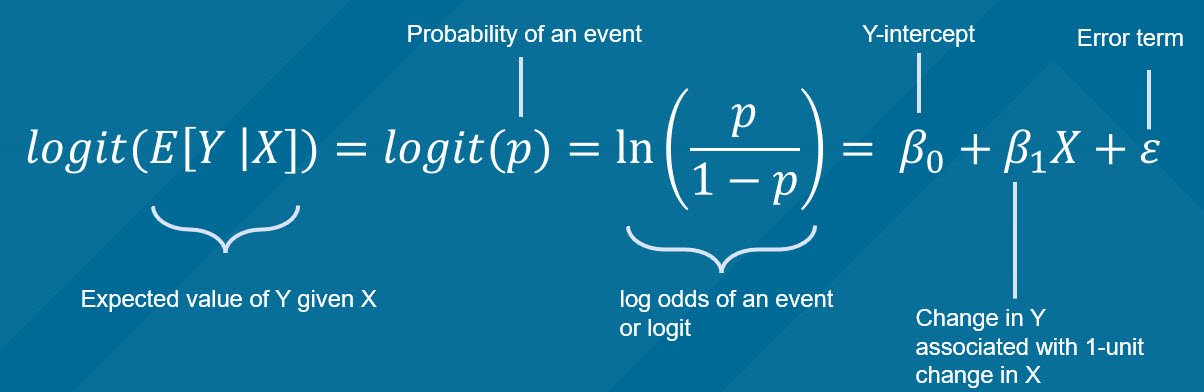Step 4. Add condition formatting rules:
Now that the data column width and row height have been set properly, you can add the conditional formatting rules to change the color of the boxes to reflect the deviations from the number of expected death (%) due to COVID-19.
First, select all the data. Then go to the Home tab and select “Conditional Formatting.” Make sure to click on “New Rule...” Select the “3-Color Scale” because we will use the gradient levels to create our heat map. The darker color will denote the higher deviations and the lighter color will denote the low or no deviations from the number of expected deaths (%). Make sure to change the “Type” to “Number.” You can enter any values that work for you, but for this example, use “0”, “0.5”, and “1” for the “Minimum”, “Midpoint”, and “Maximum” types, respectively.
Next, with the data still selected, right-click on the data to open a window. Select “Format Cells” because we want to remove the values from the cells. In the Number tab, select “Custom” and enter the following: "";"";"";"". This will change the number values so that it doesn’t show in the cells.