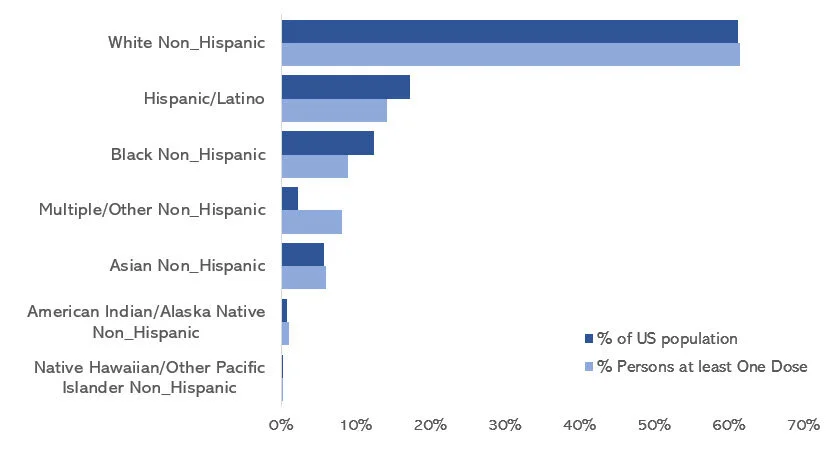
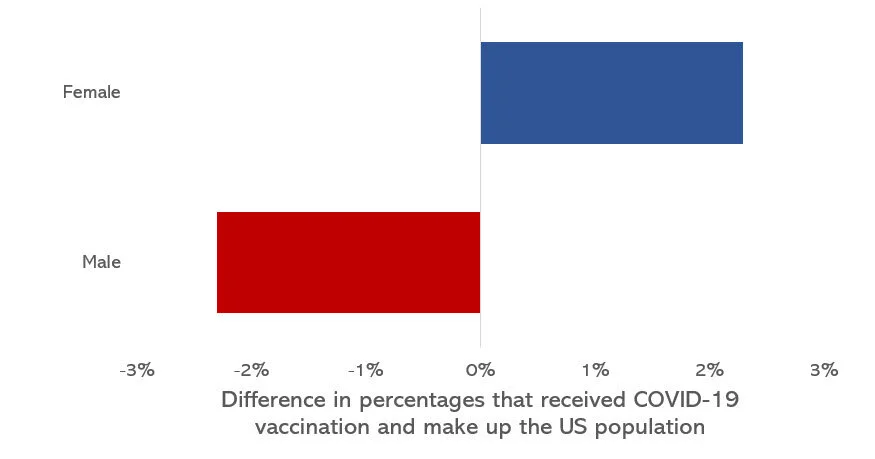
INTRODUCTION
Recently, the staff at the Los Angeles Times (LA Times) provided a COVID-19 tracker on their website. This is an impressive set of data visualizations of COVID-19 cumulative cases, new cases, vaccinations, and deaths. I was particularly struck by the “New cases by day” figure which includes a bar chart overlaid with a 7-day moving average line chart. The visualization effectively used the moving average to adjust for the spikes in new COVID-19 cases but maintained the spikes on a daily basis. None of the data are lost and illustrates the spikes in new COVID-19 cases while adjusting for the moving average. The color schemes were also optimal where the daily new cases used a softer color, but the moving average line used a darker color highlighting its importance in the figure.
I wanted to write an article on how to replicate this figure using Excel.
Source: Los Angeles Times, “Tracking the coronavirus in California,” url: https://www.latimes.com/projects/california-coronavirus-cases-tracking-outbreak/ [Accessed on June 24, 2021] * This is for educational purposes only.
DATA SOURCE
Data used in this article can be found on the LA Times GitHub site. I used the “latimes-county-totals.csv” data (link to the raw data). I also made the data available with the final figure on the following Dropbox location.
TUTORIAL
Step 1. Download and visually inspect the data.
After you’ve downloaded the data, take a moment to inspect them. The columns that are used in this tutorial are “date” and “new_confirmed_cases.” But you can use the other columns to replicate other parts of the LA Times COVID-19 tracker.
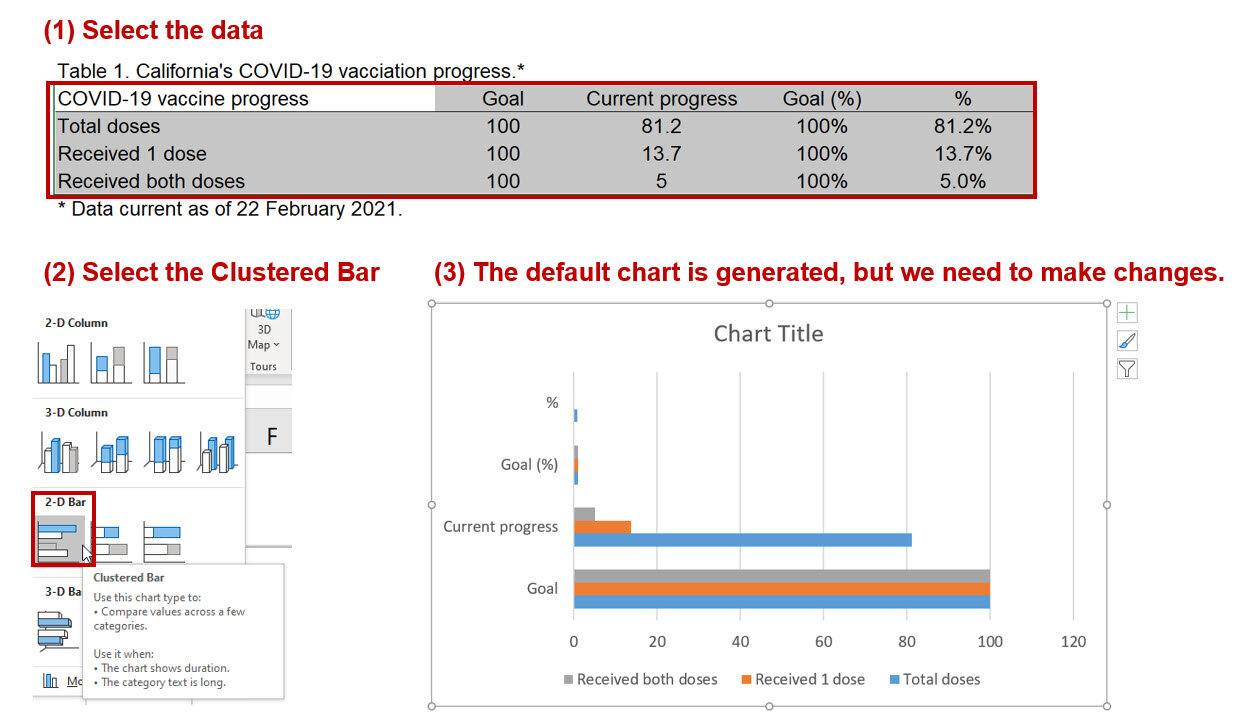
Step 2. Insert a bar chart and select the appropriate data.
Insert a clustered column chart using the Insert tab on the Excel ribbon. When selecting the data, make sure that you select the “new_confirmed_cases” (other data are available, but the new cases are what we are replicating in this exercise).
The default bar chart does a pretty good job of replicating the LA Times figure.
However, we’ll have to do a few edits to the axes to match the LA Times figure.
Step 3. Modify the axes.
Let’s focus on the Y-axis first. Right-click on the Y-axis and select “Format Axis…” In the Axis Options panel, change the Minimum value to 0 and the Major value to 20000. This will match the settings in the target figure. (Note: There are negative values in the data, but these are very small numbers and assumed to be ignorable.) Next, in the Number options, change Category to “Number” and the value in the “Decimal places” to 0. Make sure that you check the box next to “Use 1000 Separator (,)” to replicate the same format in the target figure.
For the X-axis, right-click on the bottom axis and select “Format Axis…”This will open the Axis Options panel where you can make several adjustments to the X-axis. First, we want to change the X-axis display values from dates to months. Change the Number Category field to “Custom” then change the Format Code to “mmm”; make sure to click on “Add” for the changes to take effect. Next, go to the Axis Type area and change the Minimum to “02/01/2020” since we want our timeline to begin on Feb of 2020. Then change the Major value to 4 to match the monthly interval of the target figure. The X-axis should be thicker with tick marks on the outside. To modify these, navigate to the Tick Marks option and change Major type to “Outside” and then click on the Paint Bucket (Fill & Line) option; increase the Width to 1.5. These should match the target figure’s X-axis format.
Step 4. Add the 7-day moving average.
Excel has a Data Analysis tool that will automatically estimate the 7-day average. I’ve written a previous tutorial that describes how to use this tool. I’ll briefly review how to estimate a 7-day moving average.
In the Data tab, click on the Data Analysis tool (instructions on how to install the Data Analysis tool is here). This will open the Data Analysis Tools box. Select “Moving Average” from the tools kit and enter the appropriate values in the options box. For the Input Range, select all the values from “new_confirmed_cases” column. Enter a value of “7” in the Interval field; this will automatically calculated the 7-day moving average. In the Output Range, select a single cell where you want to moving average to be pasted after it is calculated. I chose to use the next available cell on the dataset ($F$2).
Step 5. Add the 7-day moving average to the chart.
To include the moving average data to the current daily new cases bar chart, right-click on the chart and select “Select Data.” This will open a box where you can add new data. Select “Add” which will open the “Edit Series” box. Updates the Series name with the name of the column (“moving_avg”). For the Interval field, change this to “7” for the 7-day moving average. Then in the Series values, select the 7-day moving average data.
By default, Excel will generate a bar chart for the 7-day moving average. However, we want a link chart. We can change this by right-clicking on the bars of the chart and selecting “Change Series Chart Type…” This will open a box that will allow us to select the type of chart for each data. For the “moving_avg” data, change the Chart Type to “Line.” This will create a line chart for the 7-day moving average which will be overlaid over the daily new cases.
Step 6. Modifying the chart format.
To closely match the chart to the one presented in the LA Times, I made the following adjustments. Your mileage may vary depending on the library of fonts available. I tried to select fonts that most Excel users will have access to.
I changed the Y-axis font to Adabi script. The X-axis font was changed to Arial Nova.
The width of the horizontal gridlines was increased to 1.5. The color of the daily new cases bar chart was changed to a light blue using a hex code of #8DC6DF. The color of the 7-day moving average was changed to a dark blue using a hex code of #2B869B; additionally, the width was increased to 2.0.
Step 7. Comparison between LA Times and user-generated charts.
Once the modifications have been made, compare the charts.
CONCLUSIONS
Using data from the LA Times, we can replicate the data visuals on their COVID-19 tracker website. This allows users to verify the data that are presented on a public site. Additionally, it allows us to generate our own data visualizations that could inform policy and education the public on the rate of new cases in California.
REFERENCES
Data was based on the LA Times (link), which was accessed on 24 June 2021.
Excel file used for this exercise can be download from the following Dropbox folder.
ACKNOWLEDGEMENT
The data visual used in this exercise was based on the work of the staffers at the LA Times. They deserve all the credit and acknowledgement for developing these stunning visuals.