BACKGROUND
When I want to present VISN-level data, I consider using choropleths because they are visually appealing and provide a good reference to other VISNs. Choropleths are maps that uses polygons or shapes that are shaded according to a metric such that the color indicates the intensity of that metric. For instance, if you wanted to compare population density across different states, you can use a choropleth to illustrate this difference.
An example of a choropleth comes from the Centers for Disease Control and Prevention that illustrates the prevalence of obesity by state. The legend tells us the prevalence of obesity at each state and the colors denote the level of the prevalence. The cranberry color denotes an obesity prevalence of 35% or greater whereas a lighter green color with dots denotes a prevalence of less than 20%. This choropleth provides a quick visual guide on the prevalence of obesity across the United States (U.S.).

Motivating example
In past reports, I have generated a choropleth using VISN-level data. Unlike the U.S. shapefile (map files with coordinates; normally with the *.shp extension), the VISN shapefile is specific to the VA and doesn’t not follow the borders of the states used in typical U.S. shapefiles.
In this example, I will provide a step by step guide on how you can generate your own VISN-level choropleth for use in reports and presentations. The files for this tutorial are available on following Dropbox link.
TUTORIAL
Step 1: Download QGIS
Download QGIS, which is a free Geographic Information Systems (GIS) software for both the Windows and Mac operating systems. Watch the following video for a step-by-step guide on downloading and using the program. The program is simple to use and does not involve any coding. After you install the software, proceed to the next step. (Contact your local IT support to have this installed on a government-owned system.)
Step 2: Download the VISN shapefiles
The VA provides shapefiles online at the following link. (Note - 19 Feb 2026: The public link is no longer available, but the shape files are avaialble on the Dropbox link). Download the file titled FY2017_Q4_VISN.zip. This file will contain all the necessary files that you will need to build your choropleth.
Step 3: Download VISN-level data on total population
We will need VISN-level data to join with the VISN-level shapefile in QGIS. You can download the data from the following VA public site. (Note - 19 Feb 2026: The public link is no longer available, but the shape files are avaialble on the Dropbox link). Go to the Population Tables and download the “All Veterans Integrated Service Networks” Excel file. It will contain data on the total population at each VISN.
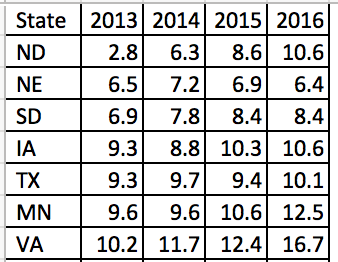
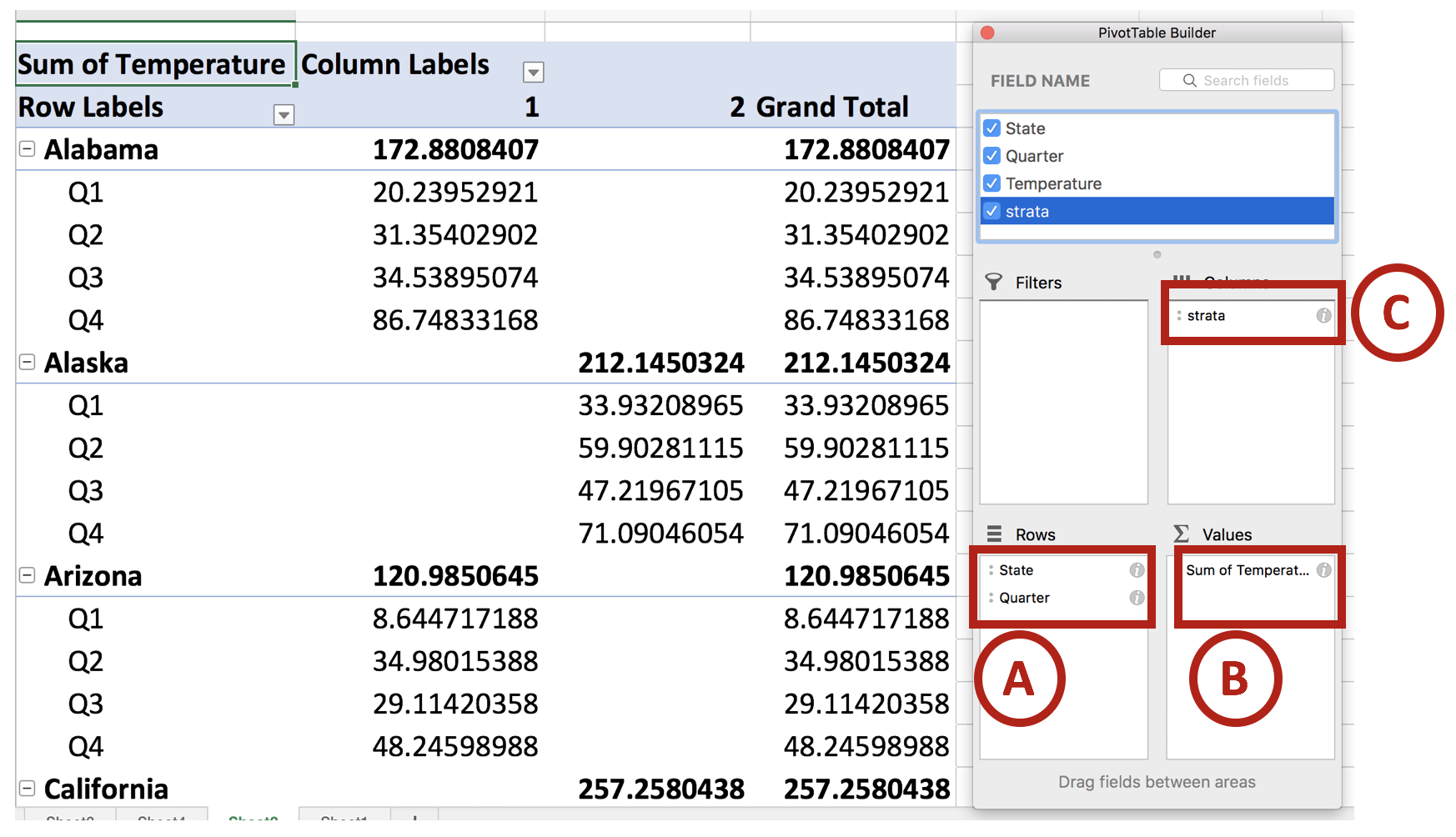
With QGIS, you will need to have two types of files for the data. I recommend using a text editor (not the Windows native notepad) such as Notepad++ or Brackets. In the text editor, open the file with the data and save it as a *.csv. The reason we do this is to make sure that the data is in text format. There are certain values that you want to ensure include the “0” in front of the other numbers (e.g., “01,” “02,” “03,” etc). If you don’t include the “0” you will not be able to join the data to the shapefiles.
After you save this as a *.csv (please include the extension onto the title), then you can open a new document on Notepad++ and enter the data column format. For instance, if column 1 is in text format, then type “String” for the first column. If the second data column is in numeric format, type “Integer.” We have a total of seven columns; therefore, we need to have seven data formats. See the example below.
Step 4: Open QGIS and add the VISN shapefile layer
Click on the Layer tab > Add Layer > Add Vector Layer and browse for the VISN shapefile.
Click on Open and make sure to click Add to add the VISN shapefile onto your QGIS software workspace. You should see the following image appear.
Notice how the polygons are in the form of the VISNs instead of the states. This is an important difference between what you see with the U.S. shapefiles and the VA shapefiles.
Step 5: Add the VISN-level population data
Include the VISN-level population data by downloading it from the VA public site. However, you can also use the Dropbox link that I host with the files already formatted for QGIS here. For this exercise, it would be easier to use the files I provide in the Dropbox link since the formatting may be challenging to implement. For more discussion about the proper formatting, please watch the following video.
You add the VISN-level population data by dragging and dropping it into the Layers panel. Use the file titled “visn_population_2018.csv” and make sure to drop it into the Layers panel. QGIS will automatically recognize the data types because the “visn_population_2018.csvt” file is in the same folder as the “visn_population_2018.csv.”
Step 6: Join the data to the shapefile
Double-click the VISN shapefile in the Layers panel; this will open a new window called the Layers Properties. Click on the JOIN icon and select the data you want to join to the VISN shapefile. Make sure to select VISN for the Join and Target field. This will use the VISN number to join the data to the shapefile. After you select OK, make sure to click on Apply.
Step 7: Adding classes and color
In the Layer Properties window, select the Symbology icon, which will open the menu to add classes and change the color of the different classes. Above the column field, select the Graduated level. In the Column field, select the visn_population_2018_Total, which is the total population of the VISN. Then select Quantile in the Mode field. Change the color ramp field to a blue hue. Click apply and you should immediately see the VISN shapefile file change colors in the workspace.
Your project workspace should look like the following map.
Step 8: Adding labels
Click on the Label icon and select the Single Labels option. Select the Labels variable and then click apply. This may take a while since QGIS has to identify the polygon’s location and insert the labels. The labeling may take about 3-5 minutes because the VISN shapefiles have layers and polygons. I recommend saving this step for when you export the final image generated using the composure function of QGIS to save yourself time.
After the labeling is done, you should see the VISN labels for each polygon.
Step 9: Use the composer to finalize your choropleth
The composer is QGIS’s workspace that allows you to customize the choropleth. Select the composer and name it “VISN population” and then select the sections you want to insert into the composer using the Adds New Map to the Layout icon. Once everything is finalized, you can export this as a *.png or *.pdf file. (At this time, you may turn on the labels if you waited to add these at the very end.)
This is what the choropleth looks like after we finish composing it.
Step 10: Add a coordinate reference system (CRS)
Right now, the map is not an accurate portrayal of the United States in relation to the surface of the Earth. It should be more round at the top due to the distance from the North Pole and the fact that the Earth is a sphere. To ensure that we are accurately portraying the U.S., we need to install the appropriate coordinate reference system (CRS). To do this we need to first click on the Properties of the project and select CRS. We add the CRS from the server using the Datum Transformations window. We change both the Source and Destination CRSs and use the USA_Contiguous_Albers_Equal_Area_Conic CRS (ID = EPSG:102003).
Once the CRS is installed into our CRS database, we can select it to change the shape of the map to correctly conform to the shape of the Earth.
This is what the choropleth looks like in the project workspace.
After we add the labels and compose the final elements, the choropleth looks like the following.
CONCLUSIONS
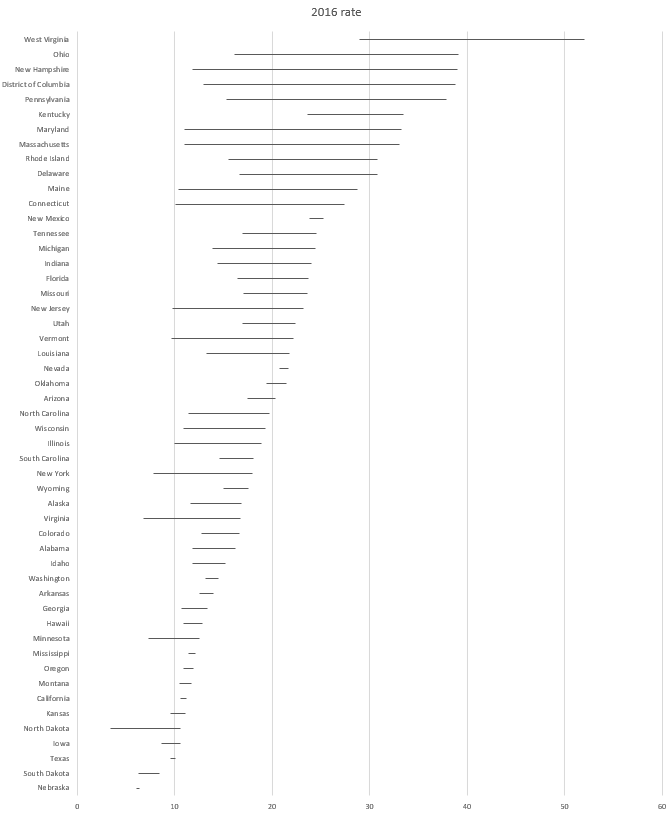
Using choropleths can highlight important differences across VISNs that would be lost in a table or difficult to present in an alternative chart. Based on the population levels, VISN 22, 17, 10 and 8 have large populations of veterans receiving care at the VA. Areas where there is low prevalence of veterans are in VISN 1, 5, 9, and 15. One thing to consider is that we did not normalize the data based on a single denominator. You can play around with how you want to do that by using the U.S. census, which can be found here. As an added exercise, see if you can create something similar using the U.S. shapefiles, which are located here. Additionally, you can use multiple choropleths (small multiples) to show changes across time or another dimension. Choropleths are excellent visuals that can contribute to a narrative; using the VISN shapefiles will allow you to generate visuals that can enhance a report or presentation.
REFERENCES
I used the following references to develop this tutorial.
https://www.youtube.com/watch?v=aLmMovuydqI&t=387s
https://www.youtube.com/watch?v=rG6UphZGmg4&t=615s
https://www.youtube.com/watch?v=LNJj3g6SRqU
Download QGIS here:
https://www.qgis.org/en/site/forusers/download
VA population data:
https://www.va.gov/vetdata/veteran_population.asp
VISN shapefiles: